
In the next article we are going to take a look at pdftotext. This is an open source command line utility that will allow us to convert PDF files to plain text files. Basically what it does is extract the text data from the PDF files. This software is free and is included by default in many Gnu / Linux distributions.
In the following lines we are going to see a tool for the terminal, but for the same purpose of extracting text from PDF files you can also use a graphical tool like Caliber. It is worth noting that both the graphical tool and the one that we can use in the terminal, they cannot extract the text if the PDF is made of images (photographs, scanned book images, etc.).
On most Gnu / Linux distributions, pdftotext is included as part of the poppler-utils package. This tool is a command line utility that convert PDF files to plain text. In it we will find many options available, including the ability to specify the range of pages to convert, the ability to keep the original physical layout of the text as well as possible, set line endings, and even work with password-protected PDF files.
Install pdftotext on Ubuntu
To install this tool on our Ubuntu system, in case you don't already have it installed, you just have to open a terminal (Ctrl + Alt + T) and write the following command in it to install poppler-utils:

sudo apt install poppler-utils
How to use pdftotext
Convert a PDF file to text
Once we have the package installed on our operating system, we can convert a PDF file to plain text. Can try to keep the original design using the option -layout with the command, but we can also try without it. In a terminal (Ctrl + Alt + T) the command to use would be the following:

pdftotext -layout pdf-entrada.pdf pdf-salida.txt
In the previous command we would have to replace pdf-input.pdf with the name of the PDF file that we are interested in converting, and pdf-output.txt by the name of the TXT file in which we want to save the text of the input PDF file. If we don't specify any output text file, pdftotext will automatically name the file with the same name as the original PDF file but with a txt extension. Another thing that can be interesting to add to the command will be the paths before the file names if necessary (~ / Documents / pdf-input.pdf).
Convert only a range of PDF pages to text
If we are not interested in converting the entire PDF file, and we want narrow down a range of PDF pages to convert to text there will be use -f option (first page to convert) Y -l (last page to convert) followed by each option with the page number. The command to use would be something like the following:
pdftotext -layout -f P -l U pdf-entrada.pdf

In the previous command you will have to replace the letters P and U with the first and last page numbers to extract. The name of pdf-input.pdf We will also have to change it and give it the name of the PDF file with which we want to work.
Use end-of-line characters
This we will be able to specify using -eol followed by mac, dos or unix. The following command will add unix line endings:
pdftotext -layout -eol unix pdf-entrada.pdf
Help
For check available options, run the man page:
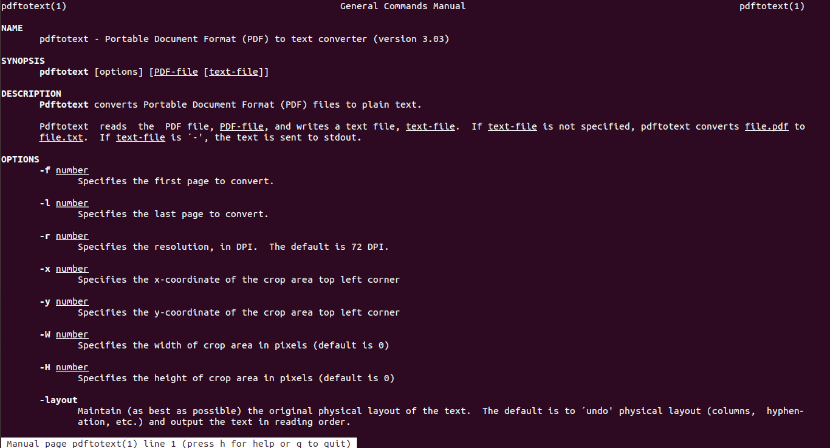
man pdftotext
It also can consult the help option with the command:
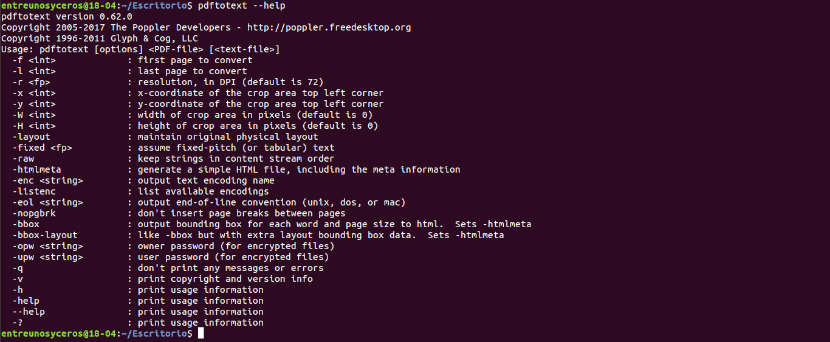
pdftotext --help
Convert PDF files from a folder using a Bash FOR loop
In case we want to convert all PDF files in a folder to text files, pdftotext does not support batch conversion from PDF to text. Esto we will be able to do it using a Bash FOR loop in terminal (Ctrl + Alt + T):
for file in *.pdf; do pdftotext -layout "$file"; done
For more information about pdftotext, you can consult the project website. In case you prefer not to have to type commands in the terminal, you can also use a online service to get the same result.
yes, well it works, but sometimes I have to do OCR or use Libre Office Draw.
In addition there are many pdf editors. and apparently this does not happen to text the images, so I do not see it practical.
And Libre Office Draw is intuitive and practical.