Kitame straipsnyje apžvelgsime TextSnatcher. Jei esate vienas iš vartotojų, kurie paprastai dirba su OCR, galbūt norėsite pamatyti paprastą programą, sukurtą ant tokios puikios sudėtingos programos, kaip ši Testeraktas. jei ieškai paprastas ir nesudėtingas būdas nukopijuoti tekstą iš vaizdų Gnu/Linux, galite pažvelgti į „TextSnatcher“, jis gali atitikti tai, ko ieškote.
Galimybė ištraukite tekstą iš vaizdų, PDF failų ar panašių dalykų, nieko naujo. Šiandien galime rasti daug įvairių įrankių šiam darbui atlikti, tačiau šiuo metu nė vienas to nedaro taip lengvai, kaip gali „TextSnatcher“.
Šis įrankis atlieka optinį simbolių atpažinimą (OCR) per kelias sekundes, o tai leis vartotojams greitai nukopijuokite tekstą iš visko, kas matoma ekrane, į sistemos mainų sritį, kad jį būtų galima įklijuoti kitur. Simbolių atpažinimas, dažnai žinomas kaip OCR (iš anglų kalbos optinio simbolių atpažinimo), yra procesas, skirtas tekstui suskaitmeninti, kuris automatiškai iš paveikslėlio atpažįsta tam tikrai abėcėlei priklausančius simbolius ar simbolius ir išsaugo juos kaip duomenis. Taigi galime su jais bendrauti naudodami teksto redagavimo programą.
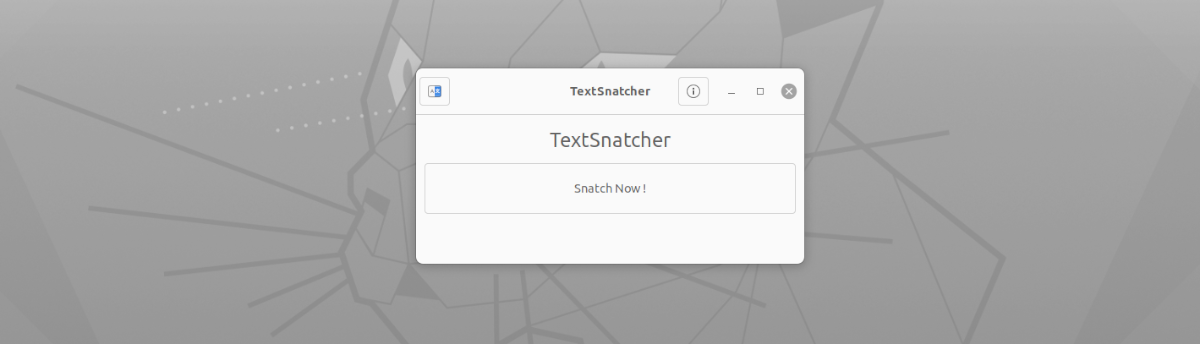
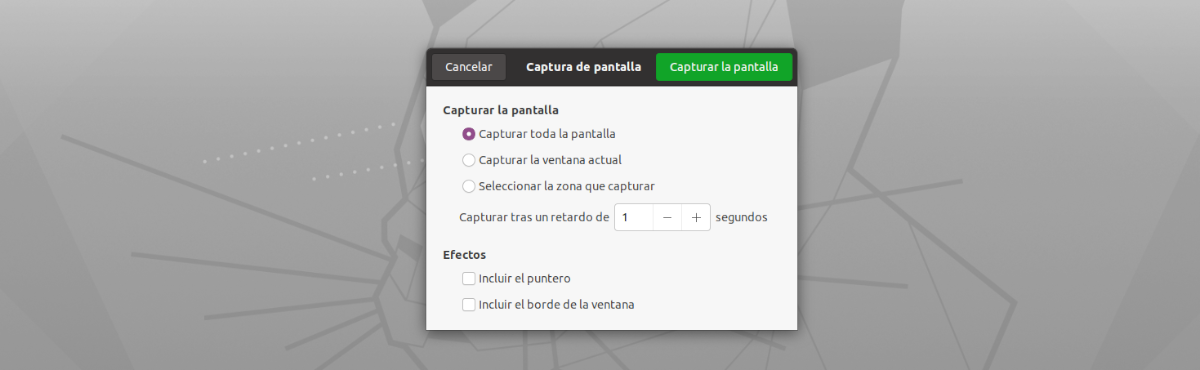
Kalbant apie šios programos sąsają, ja naudotis negali būti lengviau. Mums tereikia jį pradėti, spustelėkite mygtuką „Paimti dabar!“. Po to pamatysime numatytąjį ekrano fiksavimo įrankį, kad būtų galima užfiksuoti visą ekraną, užfiksuoti dabartinį langą arba pasirinkti sritį, kurią norite užfiksuoti (rekomenduojama) sutelkiant dėmesį tik į tekstą, kurį norime nukopijuoti.
Bendrosios TextSnatcher savybės
- Ši programa mums leis nesunkiai nukopijuokite vaizdų tekstą, OCR operacijas galime atlikti per kelias sekundes, su gana gerais rezultatais.
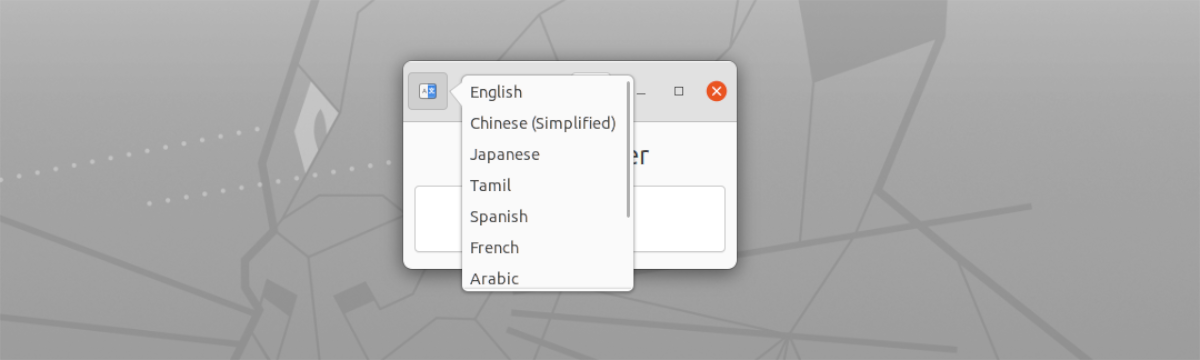
- Paskyra su kelių kalbų palaikymas. Juos galima pasirinkti mygtuku kairėje pusėje, lango viršuje.
- Leis mums nukopijuokite vaizdų tekstą pasirinkdami sritį.
- Tai yra greita ir paprasta naudoti programa.
- Jūs galite žiūrėkite kai kuriuos šios programos veikimo vaizdo įrašus savo „GitHub“ saugykla.
- Ši programa simboliams atpažinti naudoja Tesseract OCR 4.x. Jei norite sužinoti daugiau, galite perskaityti Testeraktas y „Star Tesseact“ projektas.
Įdiekite TextSnatcher Ubuntu
Ši programa galime rasti jį kaip Flatpak paketą adresu Flathubas. Jei naudojate „Ubuntu 20.04“ ir jūsų sistemoje vis dar neįgalinta ši technologija, galite tęsti Gidas kad kolega šiame tinklaraštyje prieš kurį laiką rašė.
į įdiekite šią programą Ubuntu, turėsime tik atidaryti terminalą (Ctrl + Alt + T) ir vykdyti jame esančią komandą:
flatpak install flathub com.github.rajsolai.textsnatcher
Kai programa bus baigta diegti, beliks tik ieškoti paleidimo priemonės savo kompiuteryje arba paleisti terminale, kad paleiskite programą:

flatpak run com.github.rajsolai.textsnatcher
Jei paleidus šią programinę įrangą ji neveikia tinkamai arba ji visai nepasileidžia, gali tekti ją įdiegti gnome ekrano kopija. Jei taip yra, tereikia įvesti terminalą (Ctrl+Alt+T):
sudo apt install gnome-screenshot
Pašalinti
Jei norite pašalinkite programą iš savo sistemos, reikės tik atidaryti terminalą (Ctrl+Alt+T) ir jame paleisti komandą:

flatpak uninstall com.github.rajsolai.textsnatcher
Šis įrankis skirtas skirtingoms operacinėms sistemoms. Nors norėdamas parašyti šį straipsnį, aš jį išbandžiau tik Ubuntu 20.04/21.10, abiem atvejais gavau gerų rezultatų. Variklis Tesseract OCR suteikia šio įrankio galią ir jis puikiai veikia, kai pasirinkta sritis yra didelės skyros arba kopijuojamas tekstas yra didelis ir aiškus..
Mažos skyros arba labai mažuose „teksto“ blokuose kai kurie simboliai kartais nukopijuojami į didesnius. Taip pat jei pasirinkimas turi daug dekoracijų, tai gali sukelti nesuprantamų rezultatų, nes įrankis bando priskirti teksto simbolius kraštinių dalims, vaizdams ir pan.