
在下一篇文章中,我们将研究pdftotext。 这是一个开放源代码的命令行实用程序,它将使我们能够 将PDF文件转换为纯文本文件。 基本上,它的作用是从PDF文件中提取文本数据。 该软件是免费的,并且在许多Gnu / Linux发行版中默认都包含该软件。
在以下几行中,我们将看到一个用于终端的工具,但出于从PDF文件提取文本的相同目的 您还可以使用图形工具 口径。 值得注意的是,图形工具和我们可以在终端中使用的工具, 如果PDF由图像组成,则它们无法提取文本 (照片,扫描的书籍图像等。).
在大多数Gnu / Linux发行版中, pdftotext包含在poppler-utils软件包中。 该工具是一个命令行实用程序, 将PDF文件转换为纯文本。 在其中,我们将找到许多可用的选项,包括指定要转换的页面范围的功能,尽可能保持文本原始物理布局的功能,设置行尾,甚至使用受密码保护的PDF文件的功能。 。
在Ubuntu上安装pdftotext
要在我们的Ubuntu系统上安装此工具,以防万一您尚未安装它,只需打开一个终端(Ctrl + Alt + T)并在其中写入以下命令即可: 安装poppler-utils:

sudo apt install poppler-utils
如何使用pdftotext
将PDF文件转换为文本
将软件包安装在操作系统上之后,我们可以将PDF文件转换为纯文本。 能 尝试使用选项保留原始设计 -布局 使用该命令,但是我们也可以尝试不使用它。 在终端(Ctrl + Alt + T)中,要使用的命令如下:

pdftotext -layout pdf-entrada.pdf pdf-salida.txt
在上一个命令中,我们将不得不替换 pdf输入.pdf 加上我们有兴趣转换的PDF文件的名称,以及 pdf-output.txt 我们要在其中保存输入的PDF文件的文本的TXT文件的名称。 如果我们未指定任何输出文本文件,则pdftotext会自动将文件命名为与原始PDF文件相同的名称,但扩展名为txt。 要添加到命令中的另一件有趣的事情是,如果需要的话,文件名之前的路径(〜/文件/ pdf-input.pdf).
仅将一系列PDF页面转换为文本
如果我们对转换整个PDF文件不感兴趣,我们希望 缩小PDF页面的范围以转换为文本 将有 使用-f选项 (转换首页)Y -l (最后一页要转换),然后是每个选项的页码。 使用的命令将类似于以下内容:
pdftotext -layout -f P -l U pdf-entrada.pdf

在上一个命令中,您将必须 用第一页和最后一页页码替换字母P和U 提取。 的名字 pdf输入.pdf 我们还必须对其进行更改,并为其指定要使用的PDF文件的名称。
使用行尾字符
我们可以指定 使用-eol,然后使用mac,dos或unix。 以下命令将添加unix行尾:
pdftotext -layout -eol unix pdf-entrada.pdf
帮助
至 检查可用选项,运行手册页:
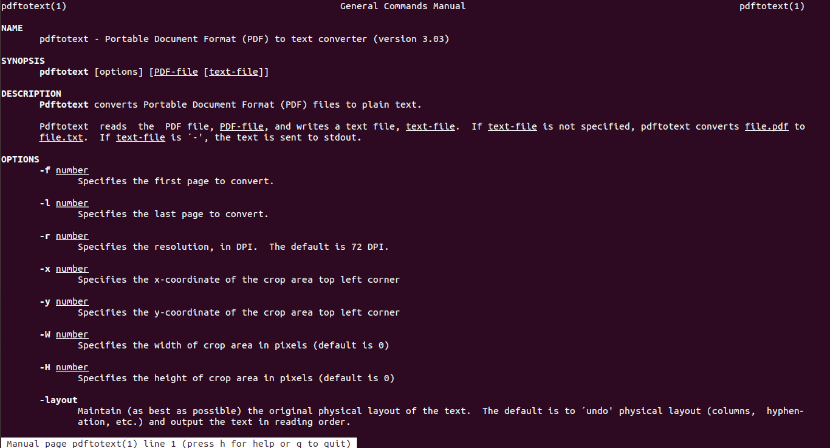
man pdftotext
你也可以 咨询帮助选项 使用命令:
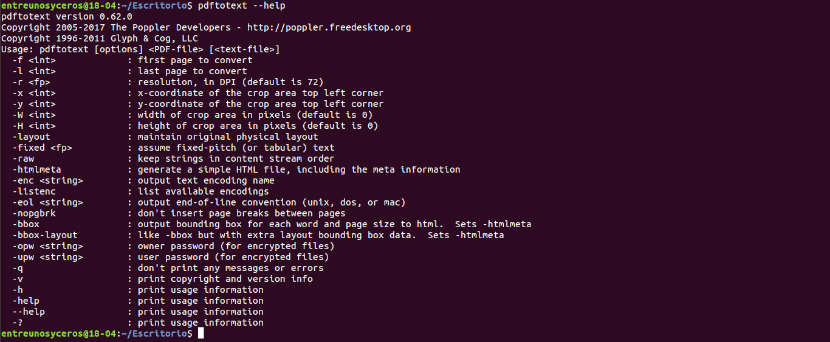
pdftotext --help
使用Bash FOR循环从文件夹转换PDF文件
如果我们要将文件夹中的所有PDF文件都转换为文本文件, pdftotext不支持从PDF到文本的批量转换。 埃斯托 我们将能够使用Bash FOR循环来做到这一点 在终端中(Ctrl + Alt + T):
for file in *.pdf; do pdftotext -layout "$file"; done
至 有关pdftotext的更多信息,您可以咨询 项目网站。 如果您不想在终端中键入命令,也可以 用一个 在线服务 得到相同的结果。
是的,它运作良好,但有时我必须执行OCR或使用Libre Office Draw。
此外,还有许多pdf编辑器。 并且显然这不会发生在文本图像上,因此我认为它不实用。
Libre Office Draw既直观又实用。