В следващата статия ще разгледаме TextSnatcher. Ако сте един от потребителите, които обикновено работят с OCR, може да искате да видите просто приложение, изградено върху страхотно сложно приложение като това тесеракт. ако търсите лесен и неусложнен начин за копиране на текст от изображения в Gnu/Linux, можете да разгледате TextSnatcher, може да отговаря на това, което търсите.
Възможността за извличане на текст от изображения, PDF файлове или подобни неща, не е нищо ново. Днес можем да намерим много различни инструменти за тази работа, но в момента никой не го прави толкова лесно, колкото TextSnatcher.
Този инструмент извършва оптично разпознаване на знаци (OCR) за секунди, което ще позволи на потребителите бързо копирайте текст от всичко видимо на екрана в системния клипборд, което го прави готов за поставяне на друго място. Разпознаване на знаци, често известно като OCR (от английско оптично разпознаване на символи), е процес, насочен към цифровизиране на текстове, които автоматично идентифицират от изображение, символи или знаци, които принадлежат към определена азбука, и след това ги съхраняват като данни. Така че можем да взаимодействаме с тях чрез програма за редактиране на текст.
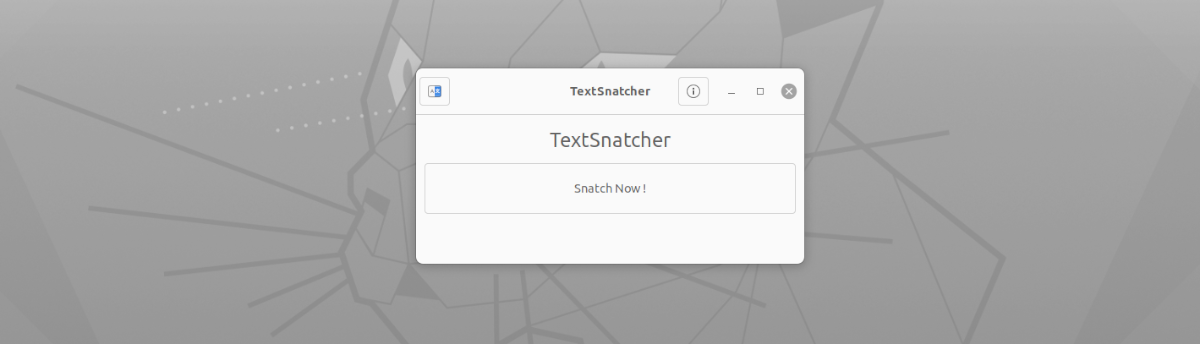
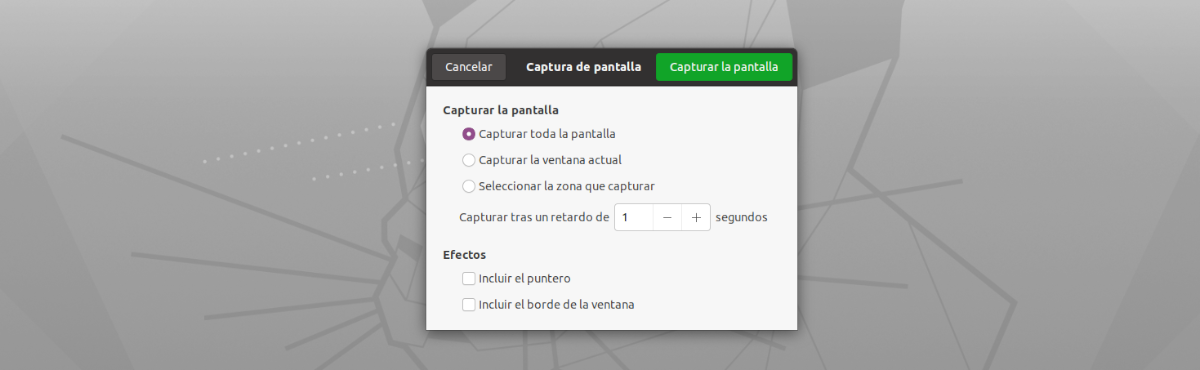
Що се отнася до интерфейса на това приложение, не може да бъде по-лесно за използване. Ще трябва само да го стартираме, щракнете върху бутона 'Snatch Now!'. След ще видим инструмента за заснемане на екрана по подразбиране, за да направи заснемане на цял екран, заснемане на текущия прозорец или да изберете област за заснемане (препоръчва се) фокусирайки се само върху текста, който искаме да копираме.
Общи характеристики на TextSnatcher
- Тази програма ще ни позволи копирайте текста на изображенията с лекота, можем да извършваме OCR операции за секунди, с доста добри резултати.
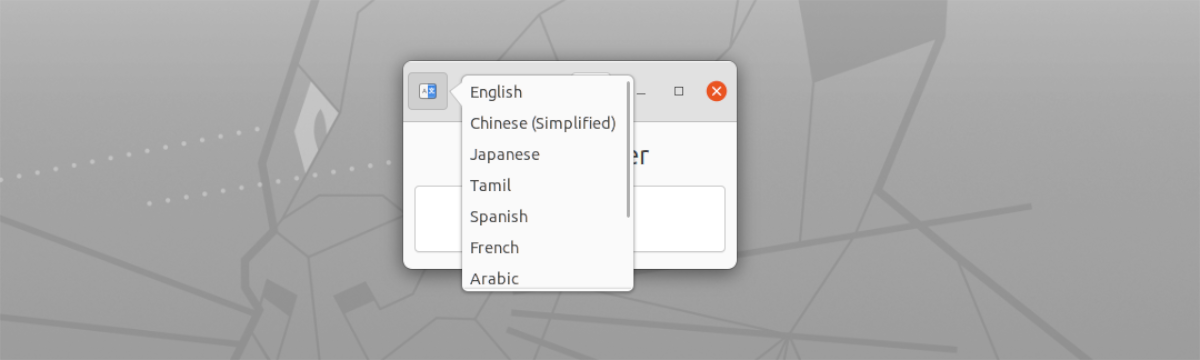
- Профил с поддръжка на няколко езика. Те могат да бъдат избрани от бутона от лявата страна, в горната част на прозореца.
- Ще ни позволи копирайте текста на изображенията, като правите селекция на областта.
- Е бърза и лесна за използване програма.
- Можете да вижте някои видеоклипове на работата на тази програма в своята Хранилище на GitHub.
- Това приложение използва Tesseract OCR 4.x за разпознаване на знаци. Ако се интересувате да научите повече, можете да прочетете за тесеракт y Звезден Тесеракт-Проект.
Инсталирайте TextSnatcher на Ubuntu
Тази програма можем да го намерим като пакет Flatpak на адрес Flathub. Ако използвате Ubuntu 20.04 и все още не сте активирали тази технология на вашата система, можете да продължите Ръководството че колега е писал в този блог преди малко.
за инсталирайте тази програма на Ubuntu, ще трябва само да отворим терминал (Ctrl + Alt + T) и да изпълним командата в него:
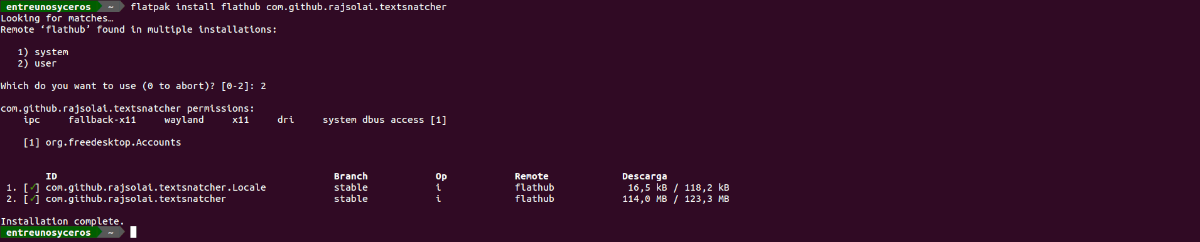
flatpak install flathub com.github.rajsolai.textsnatcher
Когато инсталацията на програмата приключи, ще трябва само да потърсим стартовия панел на нашия компютър или да стартираме в терминала, за да стартирайте програмата:

flatpak run com.github.rajsolai.textsnatcher
Ако след стартиране на този софтуер той не работи правилно или изобщо не се стартира, може да се наложи да го инсталирате екранна снимка на gnome. Ако случаят е такъв, всичко, което трябва да направите, е да въведете терминал (Ctrl+Alt+T):
sudo apt install gnome-screenshot
деинсталиране
В случай, че искате премахнете програмата от вашата система, ще е необходимо само да отворите терминал (Ctrl+Alt+T) и да стартирате командата в него:

flatpak uninstall com.github.rajsolai.textsnatcher
Този инструмент е предназначен за различни операционни системи. Въпреки че за да напиша тази статия, тествах я само на Ubuntu 20.04/21.10, с добри резултати и в двата случая. Моторът Tesseract OCR захранва този инструмент и работи чудесно, когато избраната област е с висока разделителна способност или текстът за копиране е голям и ясен..
При ниска разделителна способност или много малки блокове от „текст“, някои знаци понякога се копират в по-големи. Също така, ако селекцията има много декорации, това може да доведе до някои неразбираеми резултати, тъй като инструментът се опитва да присвои текстови знаци на части от граници, изображения и т.н.