
Poskytovatel streamované hudby Deezer, propuštěn zprávy, které nedávno se rozhodl otevřít zdrojový kód pro pilotní projekt „Spleeter“ který se vyvíjí jako systém strojového učení k oddělení zdrojů zvuku složitých zvukových skladeb. Samotný program umožňuje odstranit hlasy z kompozice a ponechat pouze hudební doprovod, manipulovat se zvukem jednotlivých nástrojů nebo upustit od hudby a nechat překrývat hlas na jiné zvukové linii, vytvářet mixy, karaoke nebo přepis.
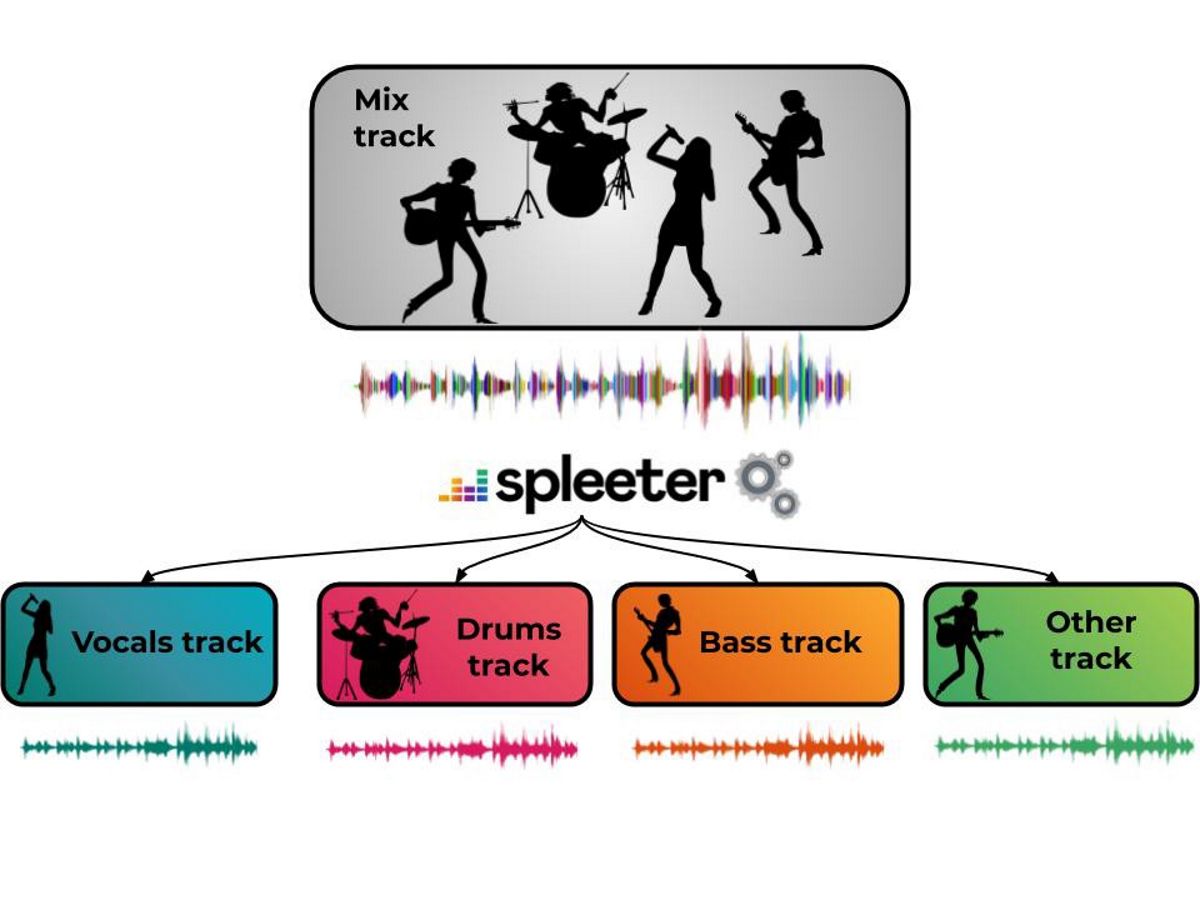
V tomto pilotním projektu „Spleeter“ nabídnout již vyškolené modely ke stažení a oddělení hlasů akustický doprovod, a také je rozdělit na 4 a 5 streamů, včetně vokálů, bicích, basů, klavíru a zbytku zvuku. Spleeter lze použít jako knihovnu Pythonu nebo jako samostatný nástroj příkazového řádku.
Při rozdělení na 2 a 4 proudy Spleeter poskytuje velmi vysoký výkonnapř. při použití GPU rozdělte zvukový soubor na 4 streamy trvá 100krát méně času než doba trvání původní skladby.
Spleeter je pod kapotou poměrně složitý a navržený motor, ale tvrdě jsme pracovali na tom, aby jeho používání bylo opravdu snadné. Skutečného oddělení lze dosáhnout pomocí jediného příkazového řádku a mělo by to fungovat na vašem notebooku bez ohledu na operační systém. Pro pokročilejší uživatele je k dispozici třída Python API s názvem Separator, se kterou můžete manipulovat přímo ve svém obvyklém kanálu.
V systému s grafickou kartou NVIDIA GeForce GTX 1080 a 6134jádrovým procesorem Intel Xeon Gold 32 bylo zpracování sběru benchmarků musDB, které trvalo tři hodiny a 27 minut, dokončeno za 90 sekund.
Z výhod nabízené společností Spleeter ve srovnání s dalším vývojem v oblasti zvukové separace, jako je otevřený projekt Open-Unmix, zmiňuje se použití lépe postavených modelů na základě rozsáhlé sbírky zvukových souborů.
Zde je důvod, proč Deezerovo rozhodnutí uvolnit kód Spleeter, protože v příspěvku o tom komentuje:
Proč spustit Spleeter?
Krátká odpověď: používáme to pro náš výzkum a myslíme si, že by to mohli chtít i ostatní.
Na oddělení zdrojů jsme pracovali dlouho (a již jsme měli příspěvek v ICASSP 2019). Porovnali jsme Spleeter s Open-Unmix, dalším modelem open source, který nedávno vydal výzkumný tým Inria, a ohlásili jsme o něco lepší výkony s vyšší rychlostí (všimněte si, že tréninková datová sada není stejná).
V neposlední řadě trénink těchto typů modelů vyžaduje spoustu času a energie. Děláme to jednou a sdílením výsledku doufáme, že ostatním ušetříme nějaké problémy a zdroje.
Z důvodu omezení autorských práv, vědci v oblasti strojového učení mají omezený přístup ke sbírkám hudebních souborů poměrně skromné modely pro veřejný přístup, zatímco pro modely Spleeter byly postaveny na základě dat z rozsáhlého hudebního katalogu Deezer.
Ve srovnání s otevřenými nástroji, jako je unmix, Spleeter pracuje přibližně o 35% rychleji v benchmarcích CPU, podporuje soubory MP3 a generuje mnohem lepší výsledky (v přidělování hlasů v Open-Undo mísí stopy některých nástrojů, které jsou pravděpodobně způsobeny tím, že modely Open-Unmix jsou trénovány ve sbírkách pouze 150 stop).
Kód projektu je dodáván ve formě knihovny v Pythonu na základě Tensorflow s předem vyškolenými modely pro oddělení přenosu 2, 4 a 5 a je distribuován pod licencí MIT. V nejjednodušším případě jsou na základě zdrojového souboru vytvořeny dva, čtyři nebo pět souborů s vokály a doprovodnými komponentami (zpěv.wav, drums.wav, bass.wav, piano.wav, other.wav).
Pokud se chcete o tomto projektu dozvědět více, můžete se poradit následující odkaz nebo můžete zkontrolovat jeho zdrojový kód v tomto odkazu.
Spleeter budou živě představeny a předvedeny na konferenci ISMIR 2019 v Delftu.