V příštím článku se podíváme na TextSnatcher. Pokud patříte mezi uživatele, kteří obvykle pracují s OCR, možná byste rádi viděli jednoduchou aplikaci postavenou na skvělé komplexní aplikaci, jako je tato Tesserakt. pokud hledáte snadný a nekomplikovaný způsob kopírování textu z obrázků v Gnu/Linuxu, můžete se podívat na TextSnatcher, protože by mohl vyhovovat tomu, co hledáte.
Možnost extrahovat text z obrázků, souborů PDF nebo podobných věcí, není nic nového. Dnes najdeme mnoho různých nástrojů, jak tuto práci provést, ale v současné době to žádný nedokáže tak snadno jako TextSnatcher.
Tento nástroj provádí optické rozpoznávání znaků (OCR) v sekundách, což uživatelům umožní rychle zkopírujte text z čehokoli viditelného na obrazovce do systémové schránky, abyste jej mohli vložit jinam. Rozpoznávání znaků, často známé jako OCR (z anglického optického rozpoznávání znaků), je proces zaměřený na digitalizaci textů, které automaticky identifikují z obrázku, symboly nebo znaky, které patří do určité abecedy, a následně je ukládají jako data. Můžeme s nimi tedy komunikovat prostřednictvím programu pro úpravu textu.
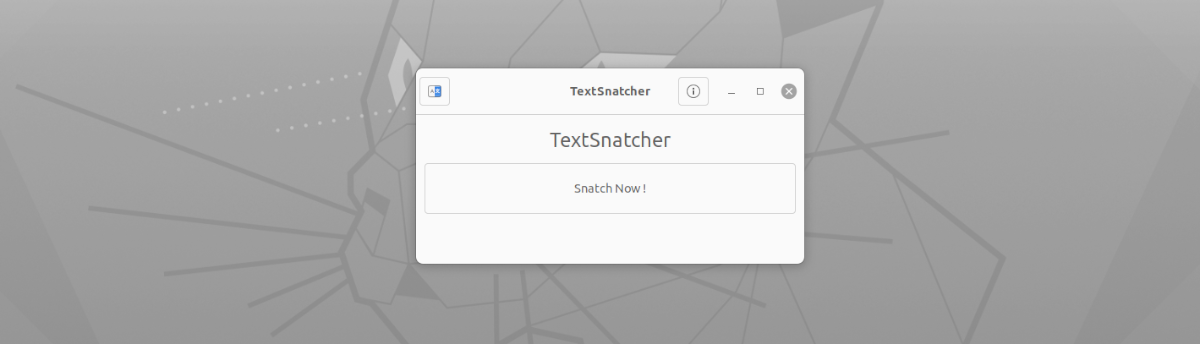
Pokud jde o rozhraní této aplikace, nemůže být jednodušší. Budeme jej muset pouze spustit, klikněte na tlačítko 'Snatch Now!'. Po uvidíme, jak se objeví výchozí nástroj pro pořízení snímku obrazovky na celou obrazovku, snímek obrazovky aktuálního okna nebo výběr oblasti k zachycení (doporučeno) se zaměřením pouze na text, který chceme zkopírovat.
Obecné vlastnosti TextSnatcheru
- Tento program nám to umožní kopírování textu obrázků s lehkostí, můžeme provádět operace OCR během několika sekund, s docela dobrými výsledky.
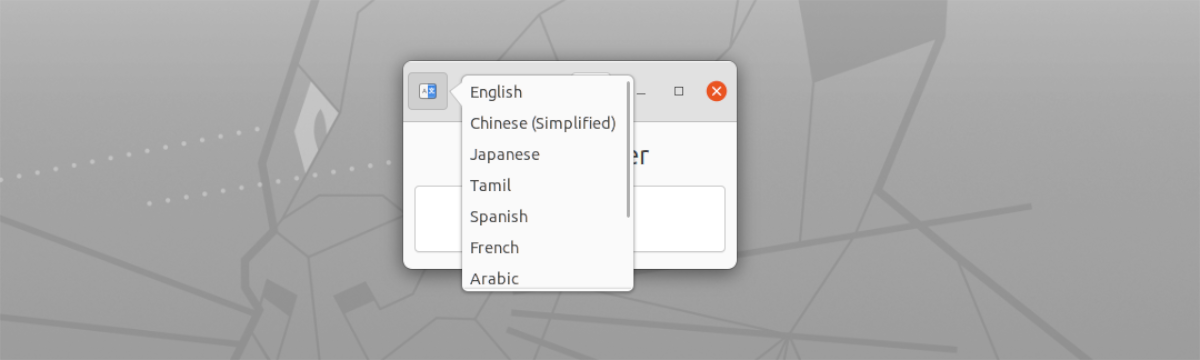
- Účet s vícejazyčná podpora. Ty lze vybrat pomocí tlačítka na levé straně v horní části okna.
- Umožní nám to zkopírujte text obrázků a vyberte oblast.
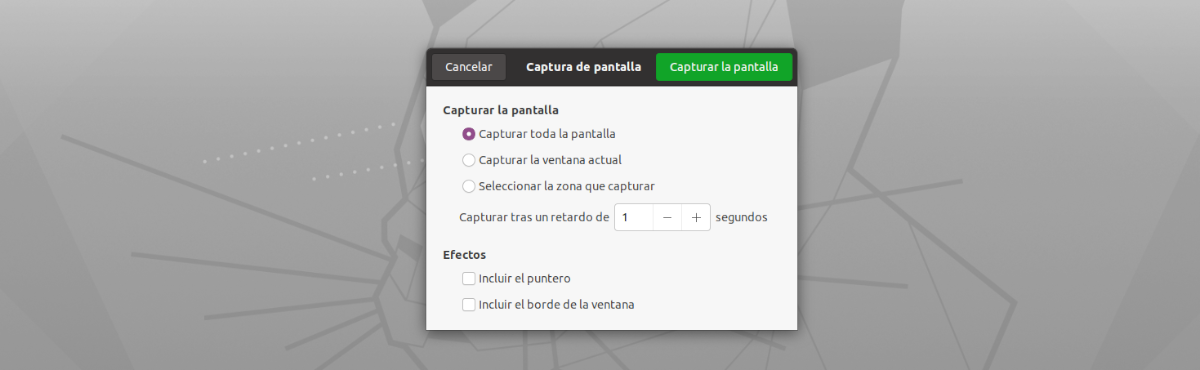
- To je rychlý a snadno použitelný program.
- Květen podívejte se na několik videí o fungování tohoto programu ve svém Úložiště GitHub.
- Tato aplikace používá Tesseract OCR 4.x pro rozpoznávání znaků. Pokud máte zájem dozvědět se více, můžete si přečíst o Tesserakt y Hvězdný projekt Tesseract.
Nainstalujte TextSnatcher na Ubuntu
Tento program najdeme jej k dispozici jako balíček Flatpak na Flathub. Pokud používáte Ubuntu 20.04 a stále nemáte tuto technologii ve svém systému povolenou, můžete pokračovat Průvodce které před chvílí napsal kolega na tomto blogu.
na nainstalovat tento program na Ubuntu, budeme muset pouze otevřít terminál (Ctrl + Alt + T) a spustit v něm příkaz:
flatpak install flathub com.github.rajsolai.textsnatcher
Po dokončení instalace programu budeme muset pouze hledat launcher na našem počítači nebo spustit v terminálu spusťte program:

flatpak run com.github.rajsolai.textsnatcher
Pokud po spuštění tento software nefunguje správně nebo se nespustí vůbec, možná budete muset nainstalovat snímek obrazovky gnome. Pokud je to váš případ, vše, co musíte udělat, je zadat terminál (Ctrl+Alt+T):
sudo apt install gnome-screenshot
Odinstalovat
V případě, že chcete odebrat program z vašeho systému, bude nutné pouze otevřít terminál (Ctrl+Alt+T) a spustit v něm příkaz:

flatpak uninstall com.github.rajsolai.textsnatcher
Tento nástroj je určen pro různé operační systémy. Ačkoli abych napsal tento článek, testoval jsem jej pouze na Ubuntu 20.04/21.10, s dobrými výsledky v obou případech. Motor Tesseract OCR pohání tento nástroj a funguje skvěle, když má vybraná oblast vysoké rozlišení nebo je text ke kopírování velký a jasný..
Ve velmi malých textových blocích nebo blocích s nízkým rozlišením jsou některé znaky někdy zkopírovány do větších. Pokud má výběr mnoho dekorací, může to vést k nepochopitelným výsledkům, protože se nástroj pokouší přiřadit textové znaky k částem ohraničení, obrázků atd.