Dans le prochain article, nous allons jeter un œil à TextSnatcher. Si vous faites partie des utilisateurs qui travaillent habituellement avec OCR, vous aimerez peut-être voir une application simple construite au-dessus d'une grande application complexe comme celle-ci Tesseract. Si vous cherchez un moyen simple et simple de copier du texte à partir d'images sous Gnu/Linux, vous pouvez jeter un œil à TextSnatcher, car cela pourrait convenir à ce que vous recherchez.
La possibilité de extraire du texte à partir d'images, de fichiers PDF ou d'éléments similaires, n'a rien de nouveau. Aujourd'hui, nous pouvons trouver de nombreux outils différents pour faire ce travail, mais pour le moment, aucun ne le fait aussi facilement que TextSnatcher.
Cet outil effectue la reconnaissance optique des caractères (OCR) en quelques secondes, ce qui permettra aux utilisateurs copiez rapidement le texte de tout ce qui est visible à l'écran dans le presse-papiers du système, ce qui le rend prêt à être collé ailleurs. La reconnaissance de caractères, souvent appelée OCR (de la reconnaissance optique de caractères anglais), est un processus visant à numériser des textes, qui identifient automatiquement à partir d'une image, des symboles ou des caractères appartenant à un certain alphabet, puis les stockent sous forme de données. Nous pouvons donc interagir avec ceux-ci via un programme d'édition de texte.
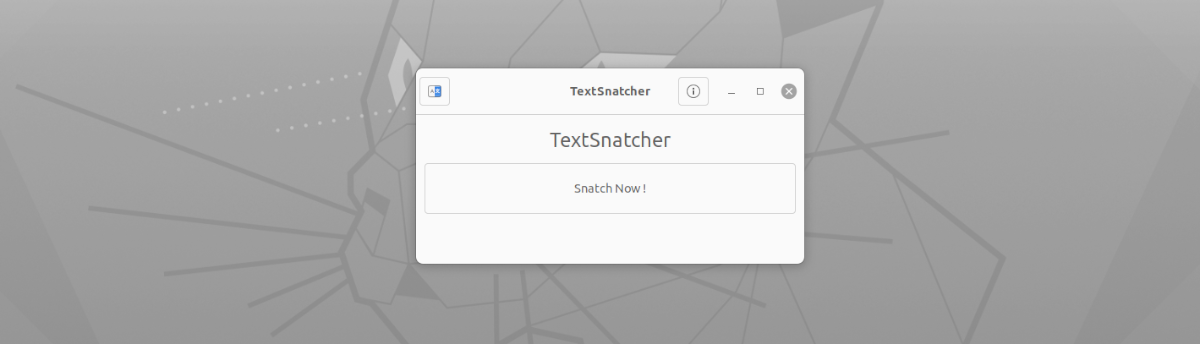
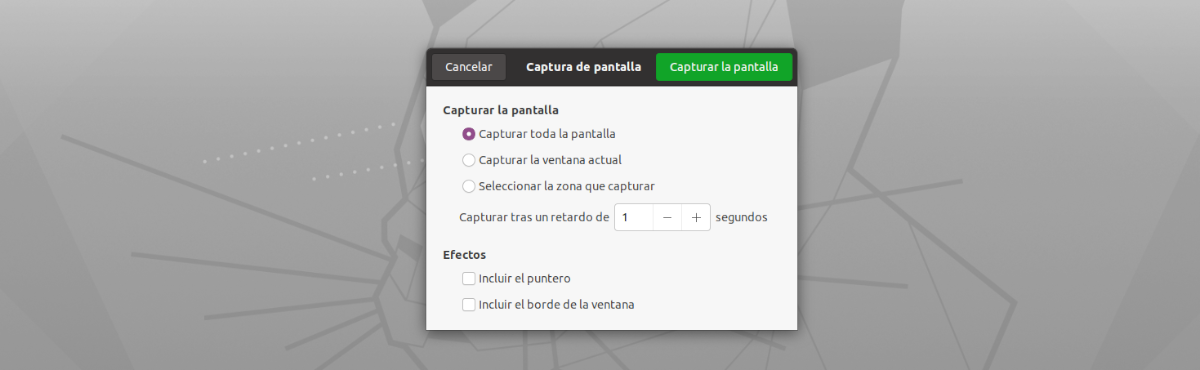
Quant à l'interface de cette application, elle ne pourrait pas être plus simple à utiliser. Nous n'aurons qu'à le démarrer, cliquez sur le bouton 'Snatch Now!'. Après on verra apparaître l'outil de capture d'écran par défaut pour faire une capture plein écran, une capture de la fenêtre en cours ou sélectionner une zone à capturer (Recommandé) en se concentrant uniquement sur le texte que nous voulons copier.
Fonctionnalités générales de TextSnatcher
- Ce programme nous permettra copiez facilement le texte des images, nous pouvons effectuer des opérations OCR en quelques secondes, avec d'assez bons résultats.
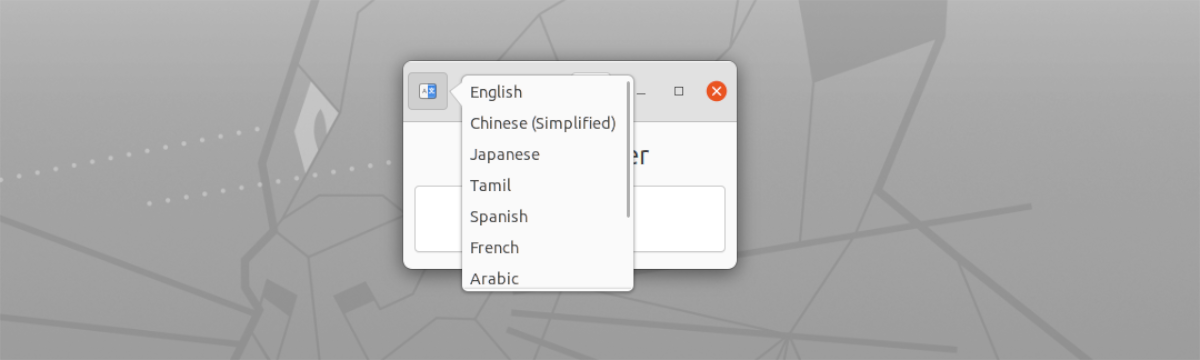
- Il a prise en charge de plusieurs langues. Ceux-ci peuvent être sélectionnés à partir du bouton sur le côté gauche, en haut de la fenêtre.
- Nous permettra copier le texte des images en faisant une sélection de la zone.
- Est un programme rapide et facile à utiliser.
- Mai voir quelques vidéos du fonctionnement de ce programme dans sa Dépôt GitHub.
- Cette application utilise Tesseract OCR 4.x pour la reconnaissance de caractères. Si vous souhaitez en savoir plus, vous pouvez lire Tesseract y Projet Star Tesseract.
Installer TextSnatcher sur Ubuntu
Ce programme nous pouvons le trouver disponible sous forme de package Flatpak à Flathub. Si vous utilisez Ubuntu 20.04 et que cette technologie n'est toujours pas activée sur votre système, vous pouvez continuer le guide qu'un collègue a écrit sur ce blog il y a quelque temps.
Pour installer ce programme sur Ubuntu, nous n'aurons qu'à ouvrir un terminal (Ctrl + Alt + T) et y exécuter la commande :
flatpak install flathub com.github.rajsolai.textsnatcher
Lorsque l'installation du programme est terminée, nous n'aurons qu'à rechercher le lanceur sur notre ordinateur, ou exécuter dans le terminal pour démarrer le programme:

flatpak run com.github.rajsolai.textsnatcher
Si après le démarrage de ce logiciel, il ne fonctionne pas correctement ou ne démarre pas du tout, vous devrez peut-être installer gnome-capture d'écran. Si c'est le cas, il suffit de taper dans un terminal (Ctrl+Alt+T) :
sudo apt install gnome-screenshot
Désinstaller
Au cas où vous voudriez supprimer le programme de votre système, il suffira d'ouvrir un terminal (Ctrl+Alt+T) et d'y lancer la commande :

flatpak uninstall com.github.rajsolai.textsnatcher
Cet outil est conçu pour différents systèmes d'exploitation. Bien que pour écrire cet article, je ne l'ai testé que sur Ubuntu 20.04/21.10, avec de bons résultats dans les deux cas. Moteur Tesseract OCR alimente cet outil et il fonctionne très bien lorsque la zone sélectionnée est en haute résolution ou que le texte à copier est grand et clair..
Dans les blocs de "texte" très petits ou de faible résolution, certains caractères sont parfois copiés dans des blocs plus grands. De plus, si la sélection comporte beaucoup de décorations, cela peut conduire à des résultats incompréhensibles, car l'outil essaie d'attribuer des caractères de texte à des parties de bordures, d'images, etc.