
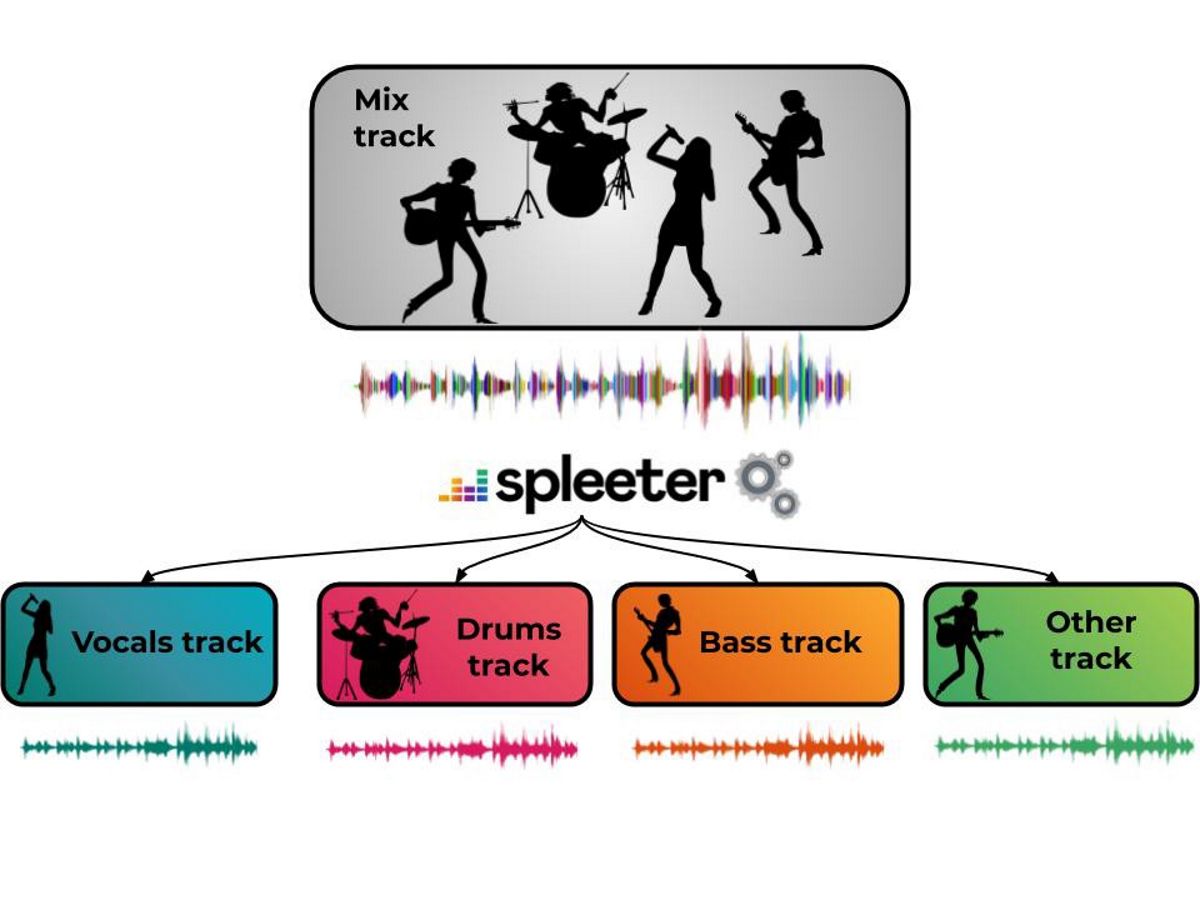
Il fornitore di musica in streaming Deezer, rilasciato la notizia che di recente ha deciso di aprire il codice sorgente per un progetto pilota "Spleeter" che si sviluppa come un sistema di machine learning per separare le sorgenti sonore di complesse composizioni sonore. Il programma stesso consente di rimuovere le voci dalla composizione e lasciare solo l'accompagnamento musicale, manipolare il suono dei singoli strumenti o rilasciare la musica e lasciare che la voce si sovrapponga a un'altra linea sonora, creare mix, karaoke o trascrizione.
In questo progetto pilota "Spleeter", offrire modelli già addestrati da scaricare e separare le voci accompagnamento acustico, oltre a dividerli in 4 e 5 flussi, inclusi voce, batteria, basso, piano e il resto del suono. Spleeter può essere utilizzato come libreria Python o come utility a riga di comando autonoma.
Quando si divide in 2 e 4 flussi, Spleeter offre prestazioni molto elevatead esempio, quando si utilizza la GPU, dividere un file audio in 4 flussi impiega 100 volte meno tempo rispetto alla durata della composizione originale.
Sotto il cofano, Spleeter è un motore abbastanza complesso e progettato, ma abbiamo lavorato duramente per renderlo davvero facile da usare. La separazione effettiva può essere ottenuta con una singola riga di comando e dovrebbe funzionare sul tuo laptop, indipendentemente dal tuo sistema operativo. Per gli utenti più avanzati, esiste una classe API Python chiamata Separator che puoi manipolare direttamente nella tua solita pipeline.
Su un sistema con una GPU NVIDIA GeForce GTX 1080 e una CPU Intel Xeon Gold 6134 a 32 core, l'elaborazione della raccolta di benchmark musDB, durata tre ore e 27 minuti, è stata completata in 90 secondi.
Dei vantaggi offerto da Spleeter, rispetto ad altri sviluppi nel campo della separazione del suono, come il progetto aperto Open-Unmix, si menziona l'uso di modelli costruiti meglio basato su un'ampia raccolta di file audio.
Ecco perché la decisione di Deezer per rilasciare il codice Spleeter, perché nel post a riguardo, commenta:
Perché lanciare Spleeter?
Risposta breve: lo usiamo per la nostra ricerca e pensiamo che anche altri potrebbero volerlo.
Lavoriamo da molto tempo sulla separazione alla fonte (e avevamo già un posto in ICASSP 2019). Abbiamo confrontato Spleeter con Open-Unmix, un altro modello open source recentemente rilasciato da un team di ricerca Inria, e abbiamo riportato prestazioni leggermente migliori con una velocità maggiore (si noti che il set di dati di addestramento non è lo stesso).
Ultimo ma non meno importante, addestrare questi tipi di modelli richiede molto tempo ed energia. Facendolo una volta e condividendo il risultato, speriamo di salvare altri problemi e risorse.
A causa delle limitazioni del copyright, ricercatori di machine learning hanno accesso limitato alle raccolte di file musicali modelli ad accesso pubblico piuttosto esigui, mentre per i modelli Spleeter sono stati costruiti utilizzando i dati dell'ampio catalogo musicale di Deezer.
In confronto a strumenti aperti come unmix, Spleeter è circa il 35% più veloce nei benchmark della CPU, supporta file MP3 e genera risultati molto migliori (nell'allocazione dei voti nell'Open-Undo mescola tracce di alcuni strumenti che sono probabilmente dovute al fatto che i modelli Open-Unmix sono addestrati in raccolte di sole 150 tracce).
Il codice del progetto si presenta sotto forma di una libreria Python basato su Tensorflow, con modelli pre-addestrati per separazione di trasmissione 2, 4 e 5 ed è distribuito con licenza MIT. Nel caso più semplice, vengono creati due, quattro o cinque file con voci e componenti di accompagnamento (vocals.wav, drums.wav, bass.wav, piano.wav, other.wav) in base al file sorgente.
Se vuoi saperne di più su questo progetto, puoi consultare il seguente collegamento oppure puoi controllare il suo codice sorgente in questo link
Spleeter sarà presentato e dimostrato dal vivo alla conferenza ISMIR 2019 a Delft.