Nākamajā rakstā mēs apskatīsim TextSnatcher. Ja esat viens no lietotājiem, kas parasti strādā ar OCR, iespējams, vēlēsities redzēt vienkāršu lietotni, kas ir izveidota uz tādas lieliskas sarežģītas lietotnes kā šī Tesseact. ja jūs meklējat vienkāršs un nesarežģīts veids, kā kopēt tekstu no attēliem Gnu/Linux, varat apskatīt TextSnatcher, jo tas varētu būt piemērots tam, ko meklējat.
Iespēja izņemiet tekstu no attēliem, PDF failiem vai līdzīgām lietām, nav nekas jauns. Šodien mēs varam atrast daudz dažādu rīku šī darba veikšanai, taču šobrīd neviens to nedara tik vienkārši, kā to spēj TextSnatcher.
Šis rīks veic rakstzīmju optisko atpazīšanu (OCR) sekundēs, kas ļaus lietotājiem ātri kopējiet tekstu no visa ekrānā redzamā teksta uz sistēmas starpliktuvi, padarot to gatavu ielīmēšanai citur. Rakstzīmju atpazīšana, bieži pazīstama kā OCR (no angļu valodas Optical Character Recognition), ir process, kura mērķis ir tekstu digitalizācija, kas pēc attēla automātiski identificē simbolus vai rakstzīmes, kas pieder noteiktam alfabētam, un pēc tam saglabā tos kā datus. Tātad mēs varam ar tiem sazināties, izmantojot teksta rediģēšanas programmu.
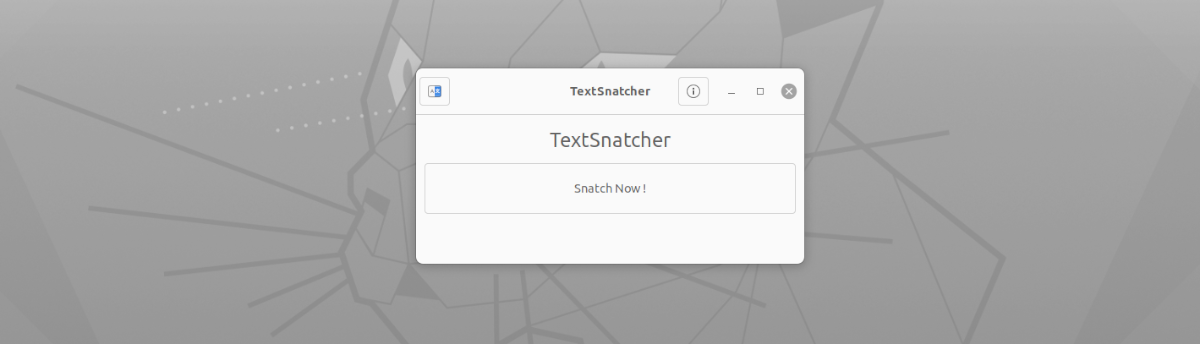
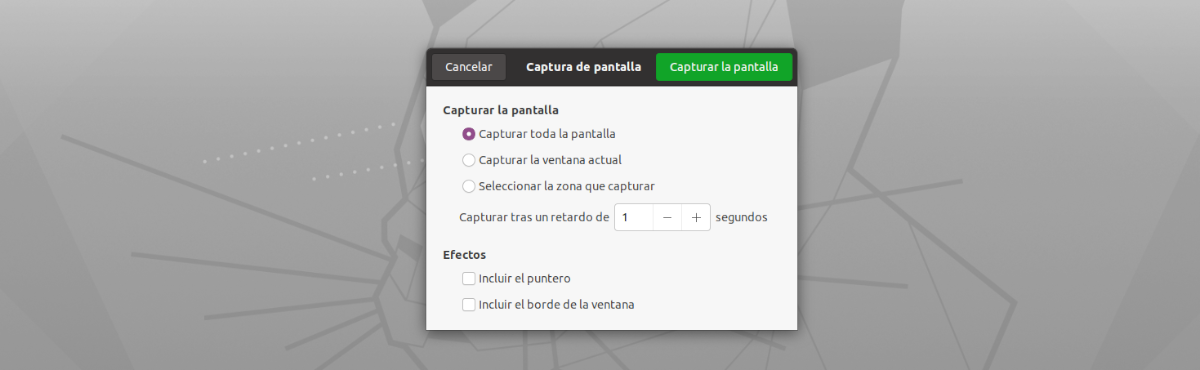
Kas attiecas uz šīs lietotnes interfeisu, tas nevar būt vienkāršāk lietojams. Mums tas būs tikai jāsāk, noklikšķiniet uz pogas 'Snatch Now!'. Pēc mēs redzēsim noklusējuma ekrāna tveršanas rīku, lai uzņemtu pilnekrāna tveršanu, pašreizējā loga tveršanu vai atlasītu apgabalu tveršanai (ieteicams), koncentrējoties tikai uz tekstu, kuru vēlamies kopēt.
TextSnatcher vispārīgās funkcijas
- Šī programma mums ļaus viegli kopēt attēlu tekstus, mēs varam veikt OCR darbības sekundēs, ar diezgan labiem rezultātiem.
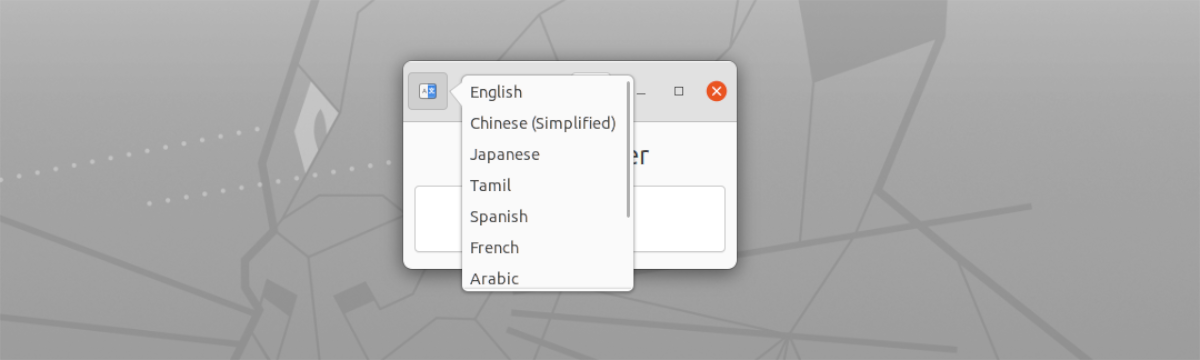
- Konts ar vairāku valodu atbalsts. Tos var izvēlēties no pogas kreisajā pusē, loga augšdaļā.
- Ļaus mums kopējiet attēlu tekstus, atlasot apgabalu.
- Tā ir ātra un viegli lietojama programma.
- Jūs varat skatiet dažus video par šīs programmas darbību STI GitHub krātuve.
- Šī lietotne rakstzīmju atpazīšanai izmanto Tesseract OCR 4.x. Ja vēlaties uzzināt vairāk, varat lasīt par Tesseact y Zvaigžņu Tesseact projekts.
Instalējiet TextSnatcher Ubuntu
Šī programma mēs to varam atrast kā Flatpak iepakojumu vietnē Flathubs. Ja izmantojat Ubuntu 20.04 un jūsu sistēmā joprojām nav iespējota šī tehnoloģija, varat turpināt Ceļvedis ka pirms kāda laika šajā emuārā rakstīja kolēģis.
līdz instalējiet šo programmu Ubuntu, mums būs tikai jāatver terminālis (Ctrl + Alt + T) un jāizpilda tajā esošā komanda:
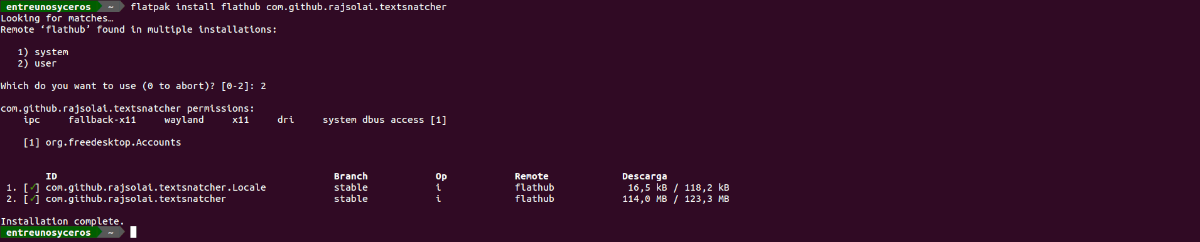
flatpak install flathub com.github.rajsolai.textsnatcher
Kad programmas instalēšana būs pabeigta, mums datorā būs tikai jāmeklē palaišanas programma vai jāskrien terminālī, lai sāciet programmu:

flatpak run com.github.rajsolai.textsnatcher
Ja pēc šīs programmatūras palaišanas tā nedarbojas pareizi vai netiek startēta vispār, iespējams, būs jāinstalē gnome ekrānuzņēmums. Ja tas tā ir, viss, kas jums jādara, ir jāievada terminālis (Ctrl+Alt+T):
sudo apt install gnome-screenshot
Atinstalēt
Gadījumā, ja vēlaties noņemiet programmu no sistēmas, būs nepieciešams tikai atvērt termināli (Ctrl+Alt+T) un palaist tajā komandu:

flatpak uninstall com.github.rajsolai.textsnatcher
Šis rīks ir paredzēts dažādām operētājsistēmām. Lai gan, lai rakstītu šo rakstu, es to pārbaudīju tikai Ubuntu versijā 20.04/21.10, ar labiem rezultātiem abos gadījumos. Motors Tesseract OCR nodrošina šo rīku, un tas lieliski darbojas, ja atlasītajam apgabalam ir augsta izšķirtspēja vai kopējamais teksts ir liels un skaidrs..
Ļoti mazos vai zemas izšķirtspējas “teksta” blokos dažas rakstzīmes dažreiz tiek kopētas uz lielākām. Arī tad, ja atlasei ir daudz dekorāciju, tas var novest pie dažiem nesaprotamiem rezultātiem, jo rīks mēģina piešķirt teksta rakstzīmes apmaļu daļām, attēliem utt.