
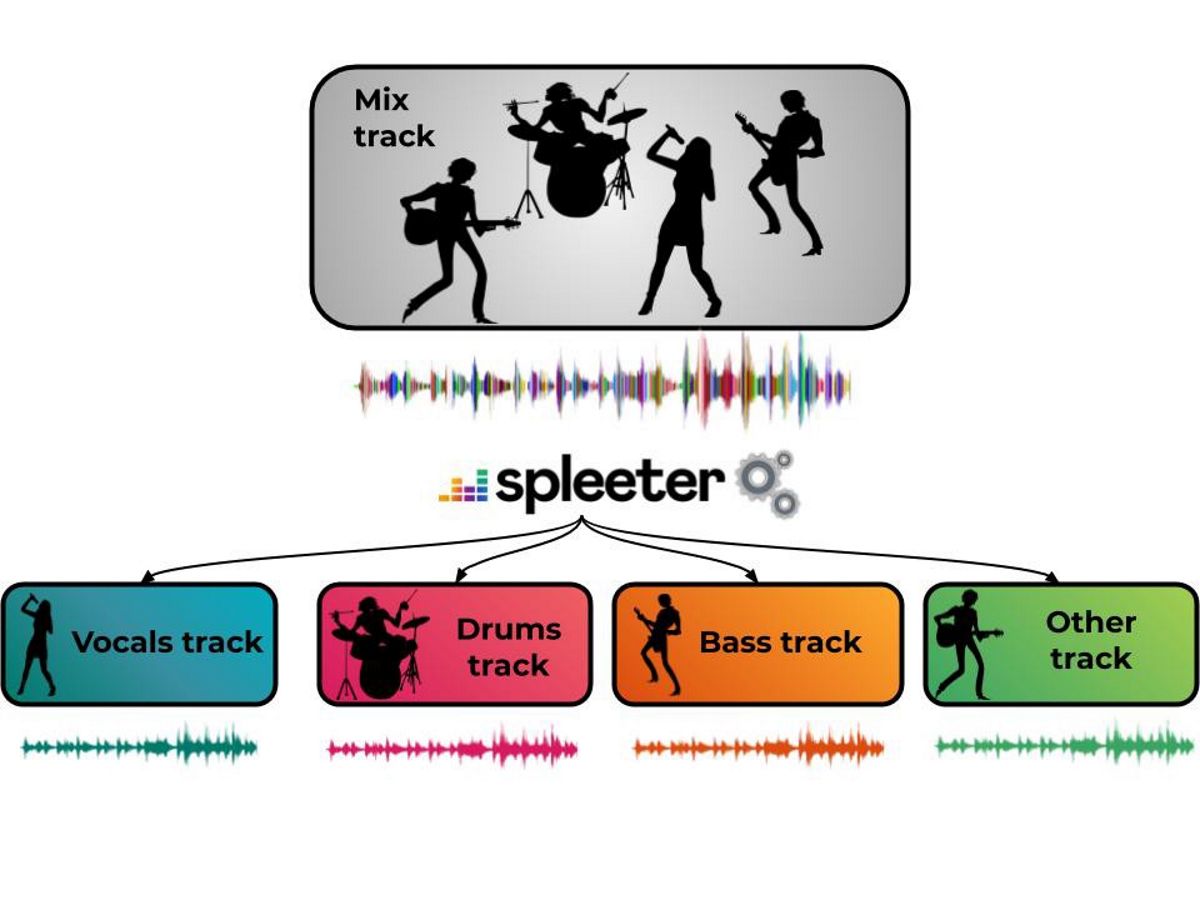
De aanbieder van streaming muziek Deezer, vrijgelaten het nieuws dat onlangs besloten om de broncode te openen voor een "Spleeter" pilootproject dat ontvouwt zich als een machine learning-systeem om geluidsbronnen te scheiden van complexe klankcomposities. Met het programma zelf kun je de stemmen uit de compositie verwijderen en alleen de muzikale begeleiding achterlaten, het geluid van individuele instrumenten manipuleren of de muziek laten vallen en de stem laten overlappen op een andere geluidslijn, mixen, karaoke of transcriptie maken.
In dit 'Spleeter'-proefproject, bieden reeds getrainde modellen om te downloaden en om de stemmen te scheiden akoestische begeleiding, en om ze te verdelen in 4 en 5 streams, inclusief zang, drums, bassen, piano en de rest van het geluid Spleeter kan worden gebruikt als een Python-bibliotheek of als een zelfstandig hulpprogramma voor de opdrachtregel.
Bij het verdelen in 2 en 4 stromen, Spleeter levert zeer hoge prestatiesBij gebruik van de GPU, splitst u een audiobestand bijvoorbeeld op in 4 streams kost 100 keer minder tijd dan de duur van de originele compositie.
Onder de motorkap is Spleeter een vrij complexe en ontworpen motor, maar we hebben er hard aan gewerkt om hem echt gebruiksvriendelijk te maken. Werkelijke scheiding kan worden bereikt met een enkele opdrachtregel en het zou op uw laptop moeten werken, ongeacht uw besturingssysteem. Voor meer gevorderde gebruikers is er een Python API-klasse genaamd Separator die u rechtstreeks in uw gebruikelijke pijplijn kunt manipuleren.
Op een systeem met een NVIDIA GeForce GTX 1080 GPU en een 6134-core Intel Xeon Gold 32 CPU, werd de musDB benchmarkverzamelingsverwerking, die drie uur en 27 minuten in beslag nam, in 90 seconden voltooid.
Van de voordelen aangeboden door Spleeter, vergeleken met andere ontwikkelingen op het gebied van klankscheiding, zoals het open Open-Unmix project het gebruik van beter gebouwde modellen wordt genoemd gebaseerd op een uitgebreide verzameling geluidsbestanden.
Dit is waarom Deezer's beslissing om de Spleeter-code vrij te geven, want in de post erover zegt hij:
Waarom Spleeter lanceren?
Kort antwoord: we gebruiken het voor ons onderzoek en we denken dat anderen dat misschien ook willen.
We zijn al heel lang bezig met bronscheiding (en hadden al een post in ICASSP 2019). We hebben Spleeter vergeleken met Open-Unmix, een ander open source-model dat onlangs is uitgebracht door een onderzoeksteam van Inria, en hebben iets betere prestaties gerapporteerd bij hogere snelheden (merk op dat de trainingsdataset niet hetzelfde is).
Last but not least kost het trainen van dit soort modellen veel tijd en energie. Door het een keer te doen en het resultaat te delen, hopen we anderen wat moeite en middelen te besparen.
Vanwege copyrightbeperkingen, machine learning-onderzoekers hebben beperkte toegang tot verzamelingen muziekbestanden vrij magere modellen voor openbare toegang, terwijl ze voor de Spleeter-modellen werden gebouwd met behulp van gegevens uit Deezer's uitgebreide muziekcatalogus.
In vergelijking met open tools zoals unmix, Spleeter presteert ongeveer 35% sneller in CPU-benchmarks, het ondersteunt mp3-bestanden en genereert veel betere resultaten (bij de toewijzing van stemmen in de Open-Undo mixt het sporen van sommige tools die waarschijnlijk te wijten zijn aan het feit dat de Open-Unmix-modellen zijn getraind in verzamelingen van slechts 150 tracks).
De projectcode komt in de vorm van een Python-bibliotheek gebaseerd op Tensorflow, met vooraf getrainde modellen voor 2, 4 en 5 transmissiescheiding en wordt gedistribueerd onder de MIT-licentie. In het eenvoudigste geval worden twee, vier of vijf bestanden met zang- en begeleidingscomponenten (vocals.wav, drums.wav, bass.wav, piano.wav, other.wav) gemaakt op basis van het bronbestand.
Als u meer wilt weten over dit project, kunt u contact opnemen met de volgende link of u kunt de broncode controleren op deze link.
spleeter wordt live gepresenteerd en gedemonstreerd op de ISMIR 2019 conferentie in Delft.