
Dostawca muzyki do przesyłania strumieniowego Deezer, zwolniony wiadomości, które niedawno postanowił otworzyć kod źródłowy pilotażowego projektu „Spleeter” który rozwija się jako system uczenia maszynowego do oddzielania źródeł dźwięku złożonych kompozycji dźwiękowych. Sam program pozwala usunąć głosy z kompozycji i pozostawić tylko akompaniament muzyczny, manipulować brzmieniem poszczególnych instrumentów lub upuścić muzykę i pozwolić głosowi na nakładanie się na inną linię dźwiękową, tworzyć miksy, karaoke czy transkrypcję.
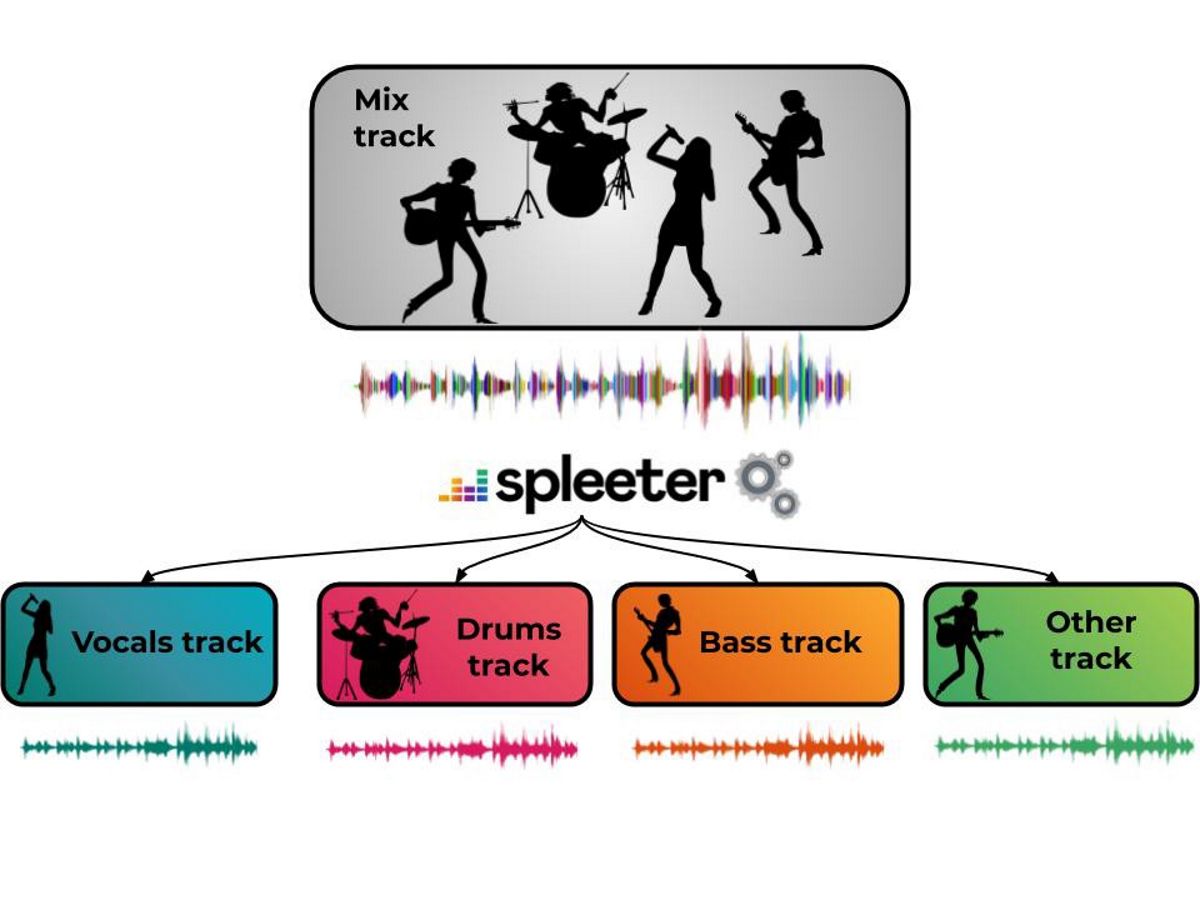
W tym pilotażowym projekcie „Spleeter” oferują już wyszkolone modele do pobrania i oddzielenia głosów akompaniament akustyczny, a także podzielić je na 4 i 5 strumieni, w tym wokale, perkusję, basy, fortepian i resztę dźwięku. Spleeter może być używany jako biblioteka Pythona lub jako samodzielne narzędzie wiersza poleceń.
Dzieląc na 2 i 4 strumienie, Spleeter zapewnia bardzo wysoką wydajnośćnp. gdy używasz GPU, podziel plik audio na 4 strumienie zajmuje 100 razy mniej czasu niż czas trwania oryginalnej kompozycji.
Pod maską Spleeter to dość złożony i zaprojektowany silnik, ale ciężko pracowaliśmy, aby był naprawdę łatwy w użyciu. Rzeczywistą separację można osiągnąć za pomocą jednego wiersza poleceń i powinno działać na Twoim laptopie, niezależnie od systemu operacyjnego. Dla bardziej zaawansowanych użytkowników dostępna jest klasa API Pythona o nazwie Separator, którą można manipulować bezpośrednio w zwykłym potoku.
W systemie z procesorem graficznym NVIDIA GeForce GTX 1080 i 6134-rdzeniowym procesorem Intel Xeon Gold 32 proces zbierania testów porównawczych musDB, który trwał trzy godziny i 27 minut, został ukończony w 90 sekund.
Z zalet oferowane przez Spleeter, w porównaniu z innymi osiągnięciami w dziedzinie separacji dźwięku, takimi jak otwarty projekt Open-Unmix, wspomina się o zastosowaniu lepiej zbudowanych modeli oparty na obszernej kolekcji plików dźwiękowych.
Oto dlaczego decyzja Deezera wypuścić kod Spleetera, bo w poście o tym komentuje:
Dlaczego warto uruchomić Spleeter?
Krótka odpowiedź: używamy go do naszych badań i uważamy, że inni też mogą tego chcieć.
Od dłuższego czasu pracujemy nad separacją u źródła (a stanowisko mieliśmy już w ICASSP 2019). Porównaliśmy Spleeter z Open-Unmix, innym modelem open source niedawno wydanym przez zespół badawczy Inria i odnotowaliśmy nieco lepszą wydajność przy większej szybkości (zauważ, że zestaw danych treningowych nie jest taki sam).
Wreszcie, trenowanie tego typu modeli zajmuje dużo czasu i energii. Robiąc to raz i dzieląc się wynikami, mamy nadzieję zaoszczędzić innym kłopotów i zasobów.
Ze względu na ograniczenia wynikające z praw autorskich, naukowcy zajmujący się uczeniem maszynowym mają ograniczony dostęp do kolekcji plików muzycznych dość skromne modele publicznego dostępu, podczas gdy w przypadku modeli Spleeter zostały one zbudowane przy użyciu danych z obszernego katalogu muzycznego Deezera.
W porównaniu z otwartymi narzędziami, takimi jak unmix, Spleeter działa około 35% szybciej w testach porównawczych procesorówobsługuje pliki MP3 i generuje znacznie lepsze wyniki (w przydziale głosów w Open-Undo miesza ślady niektórych narzędzi, co prawdopodobnie wynika z tego, że modele Open-Unmix są trenowane w zbiorach zaledwie 150 ścieżek).
Kod projektu ma postać biblioteki Python oparty na Tensorflow, z wstępnie wyszkolonymi modelami dla separacji transmisji 2, 4 i 5 i jest rozpowszechniany na licencji MIT. W najprostszym przypadku na podstawie pliku źródłowego tworzonych jest dwa, cztery lub pięć plików z wokalami i komponentami akompaniamentu (vocals.wav, drums.wav, bass.wav, piano.wav, other.wav).
Jeśli chcesz dowiedzieć się więcej o tym projekcie, możesz skonsultować się poniższy link lub możesz sprawdzić jego kod źródłowy w tym linku.
Spleetera zostaną zaprezentowane i zademonstrowane na żywo na konferencji ISMIR 2019 w Delft.