
Furnizorul de muzică în flux Deezer, eliberat vestea că recent a decis să deschidă codul sursă pentru un proiect pilot „Spleeter” care se dezvoltă ca un sistem de învățare automată pentru a separa sursele de sunet de compoziții sonore complexe. Programul în sine vă permite să eliminați vocile din compoziție și să lăsați doar acompaniamentul muzical, să manipulați sunetul instrumentelor individuale sau să lăsați muzica și să lăsați vocea să se suprapună pe o altă linie sonoră, să creați mixuri, karaoke sau transcriere.
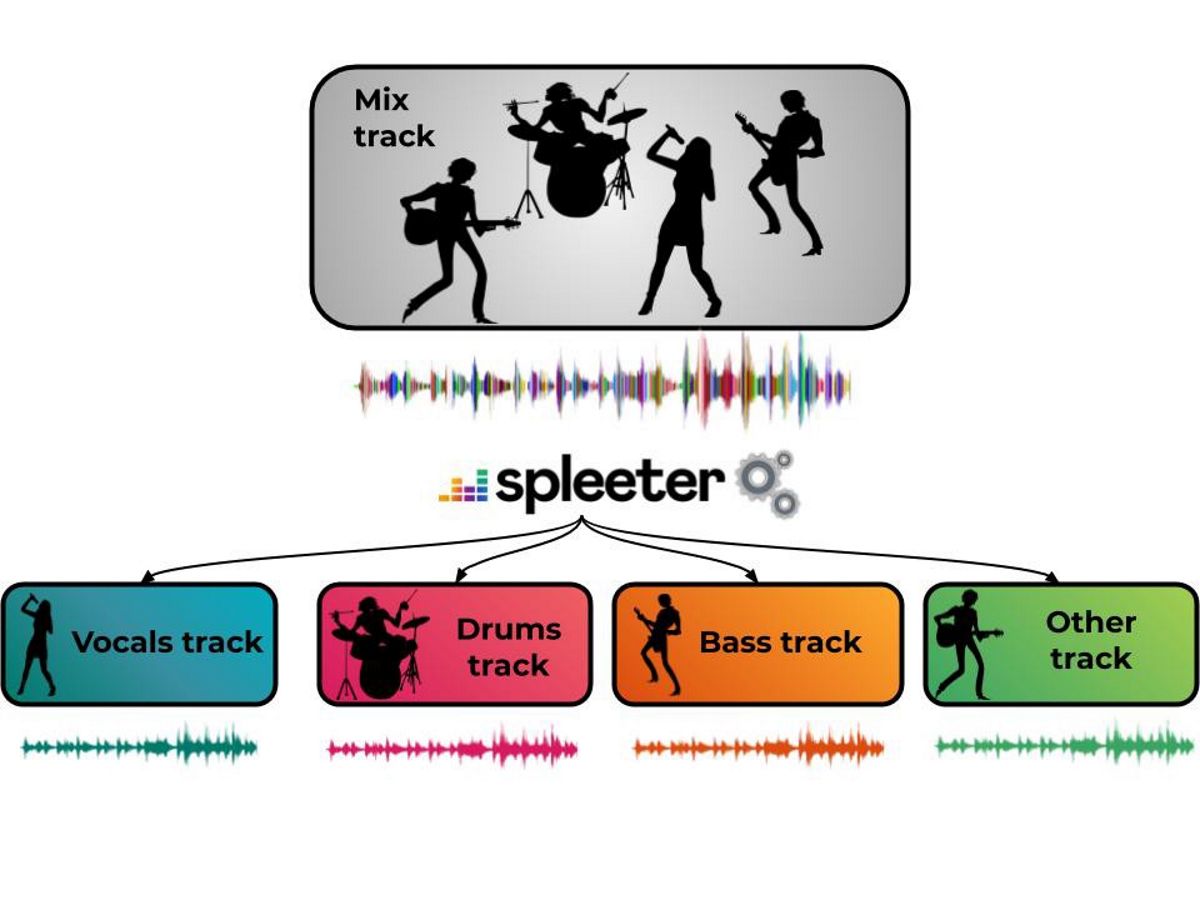
În acest proiect pilot „Spleeter”, oferă modele deja instruite pentru a descărca și a separa vocile acompaniament acustic, precum și pentru a le împărți în 4 și 5 fluxuri, inclusiv voce, tobe, bas, pian și restul sunetului. Spleeter poate fi folosit ca bibliotecă Python sau ca utilitar independent de linie de comandă.
Când vă împărțiți în 2 și 4 fluxuri, Spleeter oferă performanțe foarte ridicatede exemplu, când utilizați GPU, împărțiți un fișier audio în 4 fluxuri durează de 100 de ori mai puțin timp decât durata compoziției originale.
Sub capotă, Spleeter este un motor destul de complex și proiectat, dar am muncit din greu pentru a-l face foarte ușor de utilizat. Separarea reală poate fi realizată cu o singură linie de comandă și ar trebui să funcționeze pe laptop, indiferent de sistemul de operare. Pentru utilizatorii mai avansați, există o clasă API Python numită Separator pe care o puteți manipula direct în conducta dvs. obișnuită.
Pe un sistem cu o GPU NVIDIA GeForce GTX 1080 și un procesor Intel Xeon Gold 6134 cu 32 de nuclee, procesarea colecției de referință musDB, care a durat trei ore și 27 de minute, a fost finalizată în 90 de secunde.
Dintre avantaje oferit de Spleeter, comparativ cu alte evoluții în domeniul separării sunetului, cum ar fi proiectul deschis Open-Unmix, este menționată utilizarea modelelor mai bine construite bazat pe o colecție extinsă de fișiere audio.
Iată de ce decizia lui Deezer pentru a elibera codul Spleeter, deoarece în postarea despre el, el comentează:
De ce să lansăm Spleeter?
Răspuns scurt: îl folosim pentru cercetarea noastră și credem că și alții ar putea dori.
Lucrăm la separarea surselor de mult timp (și am avut deja o postare în ICASSP 2019). Am comparat Spleeter cu Open-Unmix, un alt model open source lansat recent de o echipă de cercetare Inria și am raportat performanțe ușor mai bune cu viteză mai mare (rețineți că setul de date de antrenament nu este același).
Nu în ultimul rând, instruirea acestor tipuri de modele necesită mult timp și energie. Făcându-l o dată și împărtășind rezultatul, sperăm să le salvăm altor probleme și resurse.
Datorită restricțiilor privind drepturile de autor, cercetători de învățare automată au acces limitat la colecțiile de fișiere muzicale modele de acces public destul de slabe, în timp ce pentru modelele Spleeter au fost construite folosind date din catalogul extins de muzică al lui Deezer.
În comparație cu instrumentele deschise, cum ar fi unmix, Spleeter efectuează cu aproximativ 35% mai rapid în benchmark-urile procesorului, acceptă fișiere MP3 și generează rezultate mult mai bune (în alocarea voturilor în Open-Undo amestecă urme ale unor instrumente care se datorează probabil faptului că modelele Open-Unmix sunt instruite în colecții de doar 150 de piese).
Codul proiectului vine sub forma unei biblioteci Python bazat pe Tensorflow, cu modele pre-antrenate pentru separarea transmisiei 2, 4 și 5 și este distribuit sub licența MIT. În cel mai simplu caz, două, patru sau cinci fișiere cu componente vocale și de acompaniament (vocals.wav, drums.wav, bass.wav, piano.wav, other.wav) sunt create pe baza fișierului sursă.
Dacă doriți să aflați mai multe despre acest proiect, puteți consulta următorul link sau îi puteți verifica codul sursă în acest link.
Spleeter va fi prezentat și demonstrat în direct la conferința ISMIR 2019 de la Delft.