În următorul articol vom arunca o privire la TextSnatcher. Dacă sunteți unul dintre utilizatorii cu care lucrează de obicei OCR, ați putea dori să vedeți o aplicație simplă construită deasupra unei aplicații complexe grozave ca aceasta Tesseract. dacă cauți o modalitate ușoară și necomplicată de a copia text din imagini în Gnu/Linux, puteți arunca o privire la TextSnatcher, deoarece s-ar putea potrivit cu ceea ce căutați.
La posibilidad de extrageți text din imagini, fișiere PDF sau lucruri similare, nu este nimic nou. Astăzi putem găsi multe instrumente diferite pentru a face acest lucru, dar în prezent niciunul nu o face la fel de ușor ca TextSnatcher.
Acest instrument realizează recunoașterea optică a caracterelor (OCR) în câteva secunde, ceea ce va permite utilizatorilor copiați rapid textul din orice lucru vizibil pe ecran în clipboard-ul sistemului, făcându-l gata de lipire în altă parte. Recunoașterea caracterelor, adesea cunoscută sub numele de OCR (din limba engleză Optical Character Recognition), este un proces care vizează digitizarea textelor, care identifică automat dintr-o imagine, simboluri sau caractere care aparțin unui anumit alfabet, iar apoi le stochează ca date. Deci putem interacționa cu acestea printr-un program de editare a textului.
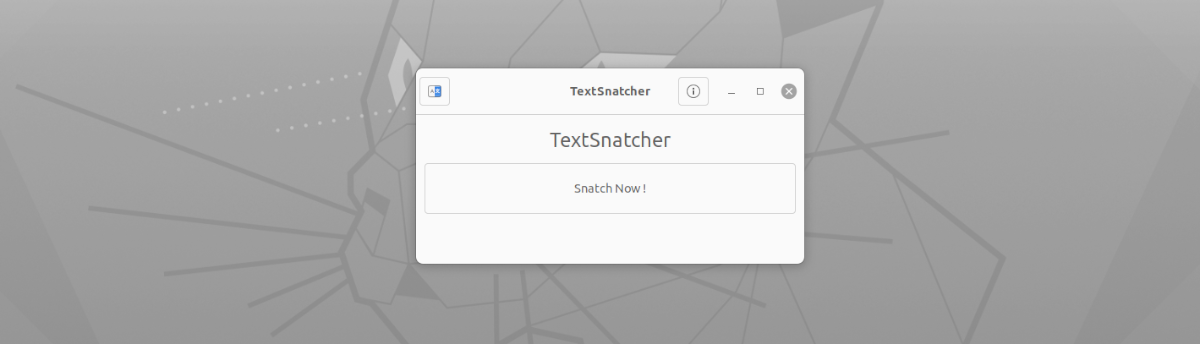
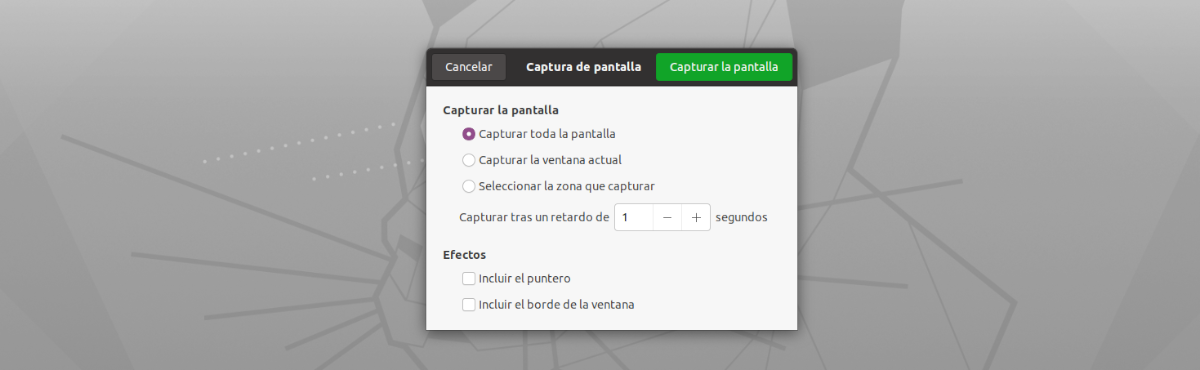
În ceea ce privește interfața acestei aplicații, nu ar putea fi mai ușor de utilizat. Va trebui doar să-l pornim, să facem clic pe butonul „Snatch Now!”. După vom vedea instrumentul implicit de capturare a ecranului care va face o captură pe ecran complet, o captură a ferestrei curente sau pentru a selecta o zonă de capturat (recomandat) concentrându-ne doar pe textul pe care dorim să-l copiem.
Caracteristici generale ale TextSnatcher
- Acest program ne va permite copiați textul imaginilor cu ușurință, putem efectua operațiuni OCR în câteva secunde, cu rezultate destul de bune.
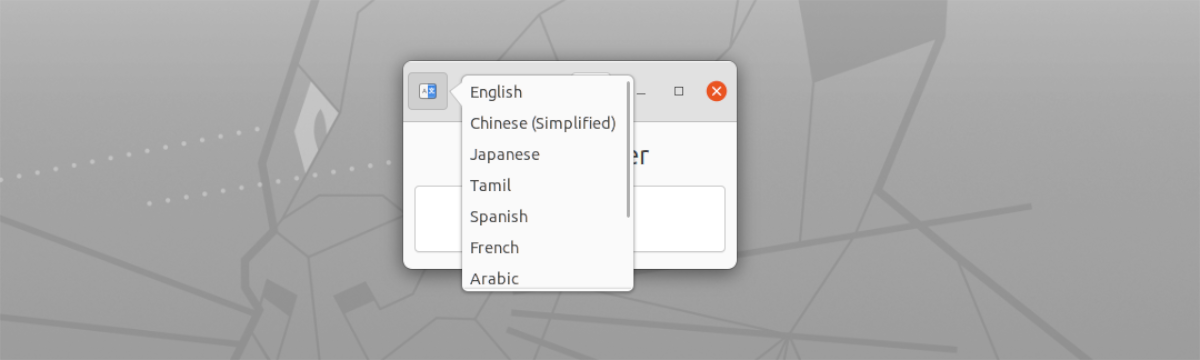
- caracteristici suport în mai multe limbi. Acestea pot fi selectate din butonul din partea stângă, în partea de sus a ferestrei.
- Ne va permite copiați textul imaginilor făcând o selecție a zonei.
- Acesta este un program rapid și ușor de utilizat.
- Poate fi vezi câteva videoclipuri cu acest program care funcționează în său Depozitul GitHub.
- Această aplicație folosește Tesseract OCR 4.x pentru recunoașterea caracterelor. Dacă sunteți interesat să aflați mai multe, puteți citi despre Tesseract y Star Tesseract-Proiect.
Instalați TextSnatcher pe Ubuntu
Acest program îl găsim disponibil ca pachet Flatpak la Flathub. Dacă utilizați Ubuntu 20.04 și încă nu aveți această tehnologie activată pe sistemul dvs., puteți continua Ghidul pe care un coleg l-a scris pe acest blog acum ceva timp.
la instalați acest program pe Ubuntu, va trebui doar să deschidem un terminal (Ctrl + Alt + T) și să executăm comanda în acesta:
flatpak install flathub com.github.rajsolai.textsnatcher
Când instalarea programului se termină, va trebui doar să căutăm lansatorul pe computerul nostru sau să rulăm în terminal pentru a porniți programul:

flatpak run com.github.rajsolai.textsnatcher
Dacă după pornirea acestui software, acesta nu funcționează corect sau nu pornește deloc, poate fi necesar să îl instalați gnome-screenshot. Dacă acesta este cazul, tot ce trebuie să faceți este să introduceți un terminal (Ctrl+Alt+T):
sudo apt install gnome-screenshot
dezinstalare
În caz că vrei eliminați programul din sistemul dvs, va fi necesar doar să deschideți un terminal (Ctrl+Alt+T) și să lansați comanda în el:

flatpak uninstall com.github.rajsolai.textsnatcher
Acest instrument este conceput pentru diferite sisteme de operare. Deși pentru a scrie acest articol, l-am testat doar pe Ubuntu 20.04/21.10, cu rezultate bune în ambele cazuri. Motorul Tesseract OCR alimentează acest instrument și funcționează excelent atunci când zona selectată este de înaltă rezoluție sau textul de copiat este mare și clar..
În blocuri de „text” cu rezoluție foarte mică sau mică, unele caractere sunt uneori copiate la dimensiuni mai mari. De asemenea, dacă selecția are mult decor, poate duce la niște rezultate de neînțeles, deoarece instrumentul încearcă să atribuie caractere text părților de chenar, imagini etc.