V naslednjem članku si bomo ogledali TextSnatcher. Če ste eden od uporabnikov, ki običajno sodelujejo s OCR, boste morda želeli videti preprosto aplikacijo, zgrajeno na vrhu odlične kompleksne aplikacije, kot je ta Teseract. če iščeš enostaven in nezapleten način kopiranja besedila iz slik v Gnu/Linuxu, si lahko ogledate TextSnatcher, saj morda ustreza temu, kar iščete.
La posibilidad de ekstrahirajte besedilo iz slik, datotek PDF ali podobnih stvari, ni nič novega. Danes lahko najdemo veliko različnih orodij za opravljanje tega dela, a trenutno ga nobeno ne naredi tako enostavno kot TextSnatcher.
To orodje izvaja optično prepoznavanje znakov (OCR) v sekundah, kar bo uporabnikom omogočilo hitro kopirajte besedilo iz česar koli vidnega na zaslonu v sistemsko odložišče, tako da je pripravljeno za lepljenje drugam. Prepoznavanje znakov, pogosto znano kot OCR (iz angleškega Optical Character Recognition), je proces, namenjen digitalizaciji besedil, ki iz slike samodejno prepoznajo simbole ali znake, ki pripadajo določeni abecedi, in jih nato shranijo kot podatke. Tako lahko s temi komuniciramo prek programa za urejanje besedil.
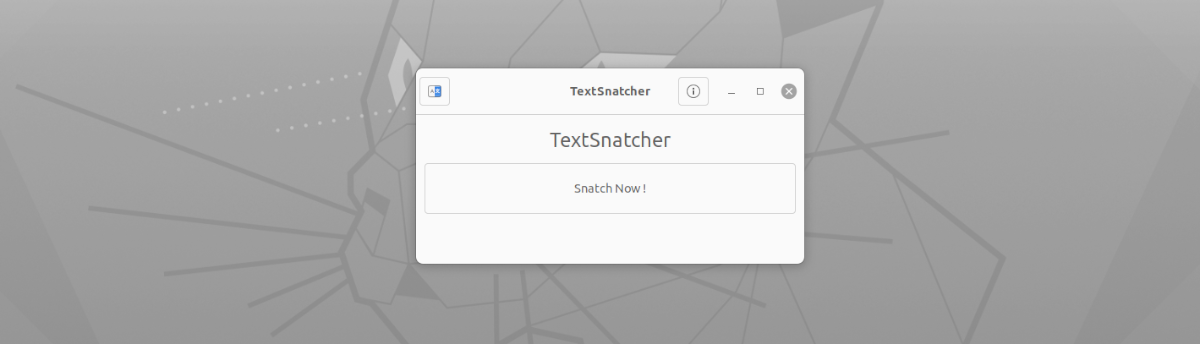
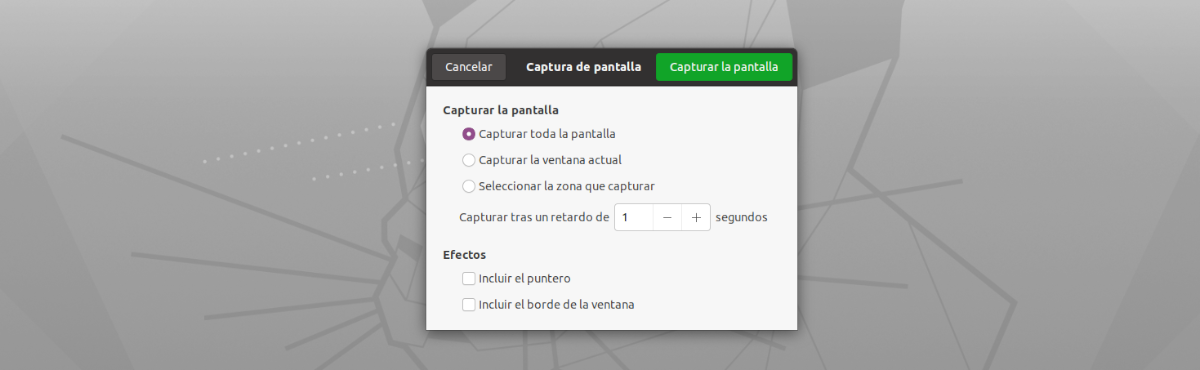
Kar se tiče vmesnika te aplikacije, ne bi mogla biti enostavnejša za uporabo. Le zagnati ga bomo morali, kliknite na gumb 'Ugrabi zdaj!'. Po videli bomo, da se prikaže privzeto orodje za zajem zaslona, da posname celozaslonski zajem, zajem trenutnega okna ali izberete območje, ki ga želite zajeti (priporočljivo) osredotočamo se samo na besedilo, ki ga želimo kopirati.
Splošne značilnosti TextSnatcherja
- Ta program nam bo omogočil z lahkoto kopiramo besedilo slik, operacije OCR lahko izvedemo v nekaj sekundah, s precej dobrimi rezultati.
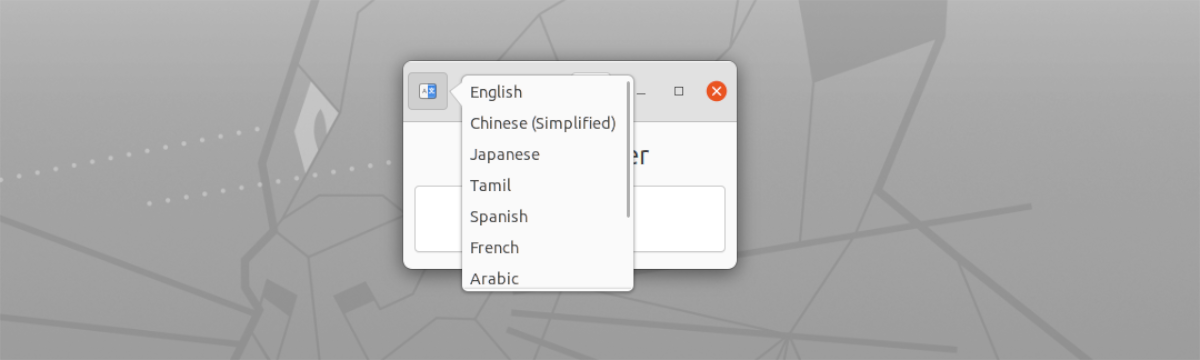
- Je podpora za več jezikov. Te lahko izberete z gumbom na levi strani, na vrhu okna.
- Nam bo dovolil kopirajte besedilo slik in tako izberete območje.
- Zato je hiter in enostaven za uporabo program.
- Lahko je Oglejte si nekaj videoposnetkov o delu tega programa v svojem Skladišče GitHub.
- Ta aplikacija uporablja Tesseract OCR 4.x za prepoznavanje znakov. Če vas zanima več, lahko preberete o Teseract y Projekt Star Tesseract.
Namestite TextSnatcher na Ubuntu
Ta program najdemo ga na voljo kot paket Flatpak na Flathub. Če uporabljate Ubuntu 20.04 in še vedno niste omogočili te tehnologije v sistemu, lahko nadaljujete Vodnik kar je pred časom na tem blogu zapisal kolega.
za namestite ta program na Ubuntu, odpreti bomo morali le terminal (Ctrl + Alt + T) in v njem izvršiti ukaz:
flatpak install flathub com.github.rajsolai.textsnatcher
Ko je namestitev programa končana, bomo morali le poiskati zaganjalnik v našem računalniku ali pa zagnati v terminalu, da zaženite program:

flatpak run com.github.rajsolai.textsnatcher
Če po zagonu te programske opreme ne deluje pravilno ali se sploh ne zažene, boste morda morali namestiti gnome-screenshot. Če je temu tako, morate samo vnesti terminal (Ctrl+Alt+T):
sudo apt install gnome-screenshot
Odstrani
V primeru, da želite odstranite program iz sistema, bo treba le odpreti terminal (Ctrl+Alt+T) in v njem zagnati ukaz:

flatpak uninstall com.github.rajsolai.textsnatcher
To orodje je zasnovano za različne operacijske sisteme. Čeprav sem ga, da bi napisal ta članek, preizkusil samo na Ubuntu 20.04/21.10, z dobrimi rezultati v obeh primerih. Motor Tesseract OCR poganja to orodje in deluje odlično, ko je izbrano območje visoke ločljivosti ali je besedilo za kopiranje veliko in jasno..
Pri nizki ločljivosti ali zelo majhnih blokih 'besedila' so nekateri znaki včasih kopirani v večje. Tudi če ima izbor veliko dekoracije, lahko pride do nekaterih nerazumljivih rezultatov, saj orodje poskuša dodeliti besedilne znake delom obrob, slik itd.