
Постачальник потокової музики Deezer, звільнений новина, яка нещодавно вирішив відкрити вихідний код для пілотного проекту "Spleeter" що розвивається як система машинного навчання для відокремлення джерел звуку складних звукових композицій. Сама програма дозволяє видалити голоси з композиції і залишити лише музичний супровід, маніпулювати звуком окремих інструментів або скинути музику і нехай голос накладається на іншу звукову лінію, створює мікси, караоке або транскрипцію.
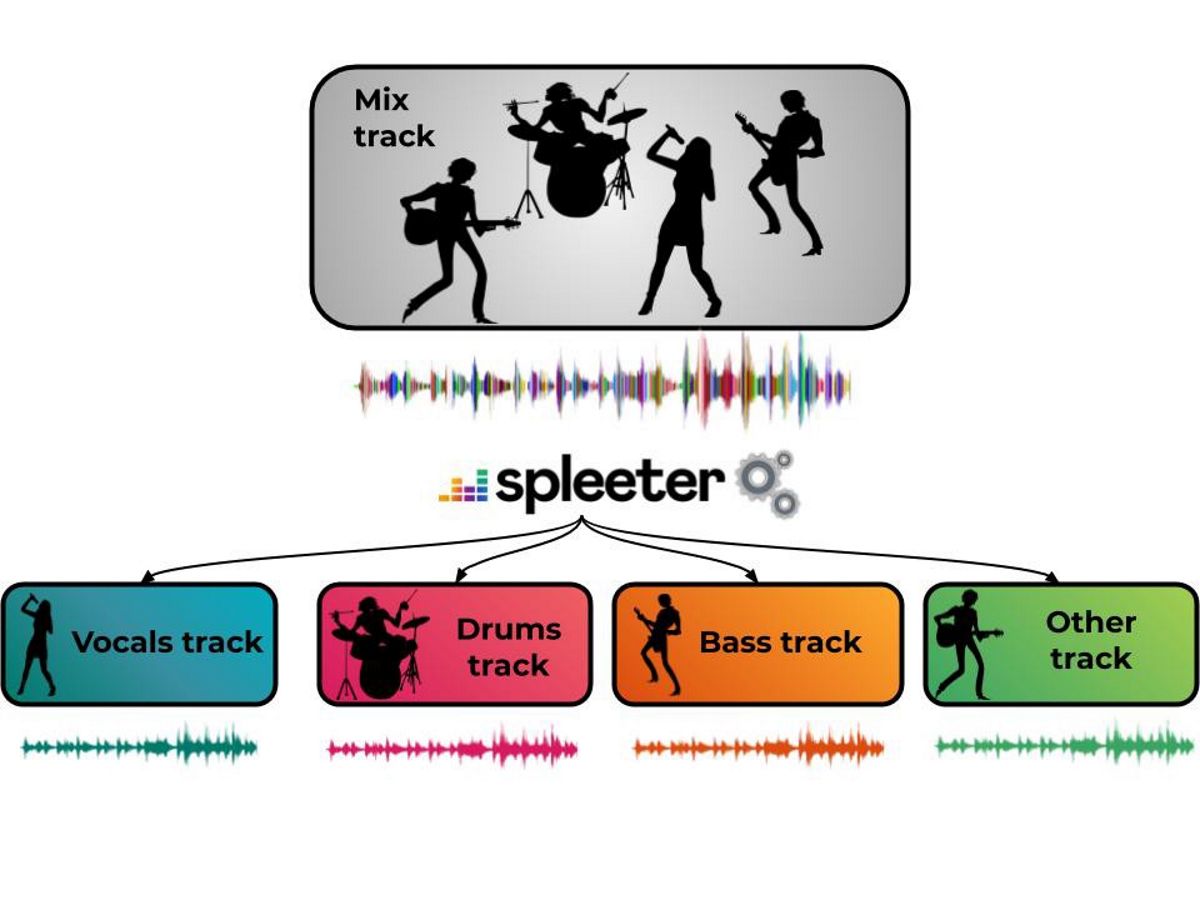
У цьому пілотному проекті "Spleeter", запропонуйте вже навчені моделі для завантаження та відокремлення голосів акустичний супровід, а також розділити їх на 4 та 5 потоки, включаючи вокал, барабани, баси, фортепіано та решту звуку. Spleeter можна використовувати як бібліотеку Python або як самостійну утиліту командного рядка.
При поділі на 2 і 4 потоки, Spleeter забезпечує дуже високу продуктивністьнаприклад, при використанні графічного процесора, розділіть аудіофайл на 4 потоки займає в 100 разів менше часу, ніж тривалість оригінальної композиції.
Під капотом Spleeter - досить складний і розроблений двигун, але ми доклали багато зусиль, щоб зробити його по-справжньому простим у використанні. Фактичного розділення можна досягти за допомогою одного командного рядка, і він повинен працювати на вашому ноутбуці, незалежно від вашої операційної системи. Для більш досвідчених користувачів існує клас Python API під назвою Separator, яким ви можете керувати безпосередньо у своєму звичайному конвеєрі.
У системі з графічним процесором NVIDIA GeForce GTX 1080 та 6134-ядерним процесором Intel Xeon Gold 32 процесор збору тестів musDB, який тривав три години 27 хвилин, був завершений за 90 секунд.
З переваг пропонований Spleeter, порівняно з іншими розробками в галузі розділення звуку, такими як відкритий проект Open-Unmix, згадується використання краще побудованих моделей на основі великої колекції звукових файлів.
Ось чому рішення Дізера звільнити код Сплітера, оскільки у дописі про це він коментує:
Навіщо запускати Spleeter?
Коротка відповідь: ми використовуємо його для своїх досліджень, і ми думаємо, що це можуть захотіти й інші.
Ми вже давно працюємо над розділенням джерел (і ми вже мали допис у ICASSP 2019). Ми порівняли Spleeter з Open-Unmix, іншою моделлю з відкритим кодом, нещодавно випущеною дослідницькою групою Inria, і повідомили про дещо кращі показники з вищою швидкістю (зауважте, що навчальний набір даних не однаковий).
І останнє, але не менш важливе: навчання таких моделей займає багато часу та енергії. Зробивши це один раз і поділившись результатом, ми сподіваємось заощадити іншим деякі проблеми та ресурси.
Через обмеження авторських прав, дослідники машинного навчання мають обмежений доступ до колекцій музичних файлів досить мізерні моделі загального доступу, тоді як для моделей Spleeter вони були побудовані з використанням даних з великого музичного каталогу Deezer.
У порівнянні з відкритими інструментами, такими як unmix, Spleeter працює приблизно на 35% швидше в тестах процесора, він підтримує файли MP3 і дає набагато кращі результати (при розподілі голосів у програмі Open-Undo він змішує сліди деяких інструментів, які, ймовірно, пов'язані з тим, що моделі Open-Unmix навчаються у колекціях лише з 150 композицій).
Код проекту подається у формі бібліотеки Python на основі Tensorflow, з попередньо навченими моделями для розділення передач 2, 4 і 5 і поширюється за ліцензією MIT. У найпростішому випадку на основі вихідного файлу створюються два, чотири або п’ять файлів з вокалом та компонентами акомпанементу (vocals.wav, drums.wav, bass.wav, piano.wav, other.wav).
Якщо ви хочете дізнатись більше про цей проект, ви можете проконсультуватися за наступним посиланням або ви можете перевірити його вихідний код за цим посиланням.
Пишніше будуть представлені та продемонстровані в прямому ефірі на конференції ISMIR 2019 у Делфті.