У наступній статті ми збираємося поглянути на TextSnatcher. Якщо ви один із користувачів, з якими зазвичай працюєте OCR, можливо, вам захочеться побачити просту програму, створену поверх такої великої складної програми, як ця Тессеракт. якщо ви шукаєте простий і нескладний спосіб копіювати текст із зображень у Gnu/Linux, ви можете подивитись на TextSnatcher, він може підійти саме тому, що ви шукаєте.
Можливість витягувати текст із зображень, файлів PDF або подібних речей, нічого нового. Сьогодні ми можемо знайти багато різних інструментів для виконання цієї роботи, але на даний момент жоден не робить це так легко, як TextSnatcher.
Цей інструмент виконує оптичне розпізнавання символів (OCR) за секунди, що дозволить користувачам швидко скопіювати текст з будь-якого видимого на екрані в системний буфер обміну, щоб він був готовий до вставлення в інше місце. Розпізнавання символів, часто відоме як OCR (з англійської Optical Character Recognition), це процес, спрямований на оцифрування текстів, які автоматично ідентифікують із зображення, символи чи символи, що належать до певного алфавіту, а потім зберігають їх як дані. Тож ми можемо взаємодіяти з ними за допомогою програми для редагування тексту.
Що стосується інтерфейсу цього додатка, він не може бути простіше у використанні. Нам залишиться лише запустити його, натиснувши кнопку «Вирвати зараз!». Після ми побачимо, що інструмент зйомки екрана за замовчуванням з’явиться, щоб зробити повний знімок екрана, зйомку поточного вікна або вибрати область для захоплення (рекомендується) зосереджуючись лише на тексті, який ми хочемо скопіювати.
Загальні особливості TextSnatcher
- Ця програма дозволить нам копіюйте текст зображень з легкістю, ми можемо виконувати операції OCR за лічені секунди, з досить хорошими результатами.
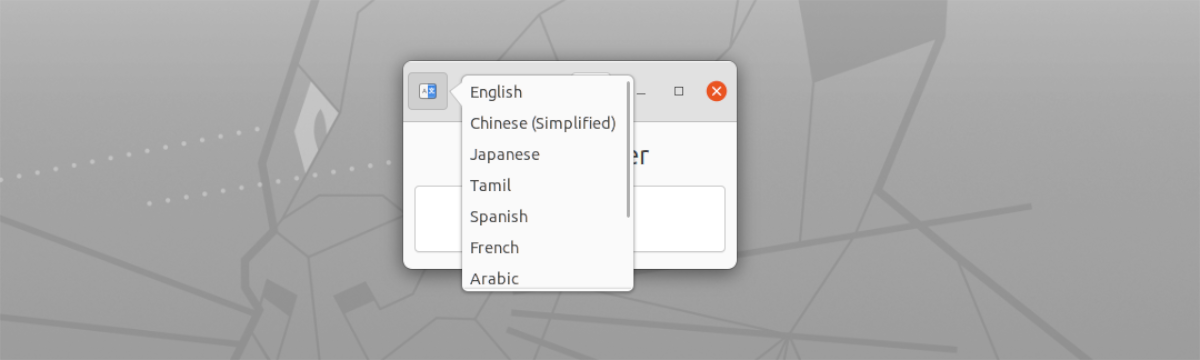
- Має підтримка кількох мов. Їх можна вибрати за допомогою кнопки зліва, у верхній частині вікна.
- Дозволить нам скопіюйте текст зображень, виділивши область.
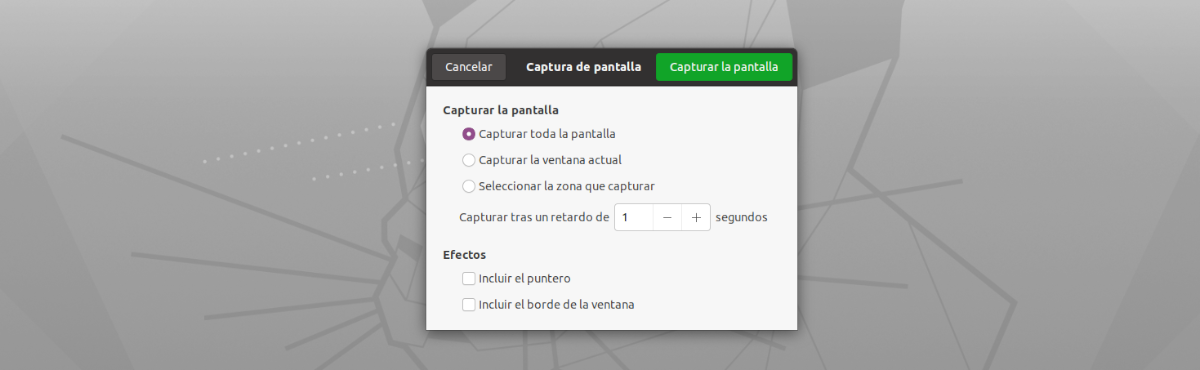
- Це швидка та проста у використанні програма.
- Ви можете подивіться деякі відео роботи цієї програми У своєму Репозиторій GitHub.
- Це додаток використовує Tesseract OCR 4.x для розпізнавання символів. Якщо вам цікаво дізнатися більше, ви можете прочитати про Тессеракт y Зірковий Тессеракт-Проект.
Встановіть TextSnatcher на Ubuntu
Ця програма ми можемо знайти його доступним у вигляді пакета Flatpak за адресою Флатхуб. Якщо ви використовуєте Ubuntu 20.04, але у вас все ще не увімкнено цю технологію у вашій системі, ви можете продовжити Керівництво що колега писав у цьому блозі деякий час тому.
в встановити цю програму на Ubuntu, нам залишиться тільки відкрити термінал (Ctrl + Alt + T) і виконати в ньому команду:
flatpak install flathub com.github.rajsolai.textsnatcher
Коли інсталяція програми буде завершена, нам залишиться лише шукати панель запуску на нашому комп’ютері або запустити в терміналі, щоб запустити програму:

flatpak run com.github.rajsolai.textsnatcher
Якщо після запуску це програмне забезпечення не працює належним чином або не запускається взагалі, можливо, вам знадобиться інсталювати gnome-скріншот. Якщо це так, все, що вам потрібно зробити, це ввести в термінал (Ctrl+Alt+T):
sudo apt install gnome-screenshot
Видаліть
У випадку, якщо ви хочете видалити програму зі своєї системи, потрібно буде лише відкрити термінал (Ctrl+Alt+T) і запустити в ньому команду:

flatpak uninstall com.github.rajsolai.textsnatcher
Цей інструмент розроблений для різних операційних систем. Хоча, щоб написати цю статтю, я тестував її лише на Ubuntu 20.04/21.10, з хорошими результатами в обох випадках. Двигун Tesseract OCR підтримує цей інструмент, і він чудово працює, коли виділена область має високу роздільну здатність або текст для копіювання великий і чіткий..
У дуже малих або низьких «текстових» блоках деякі символи іноді копіюються до більших. Крім того, якщо виділення має багато декору, це може призвести до незрозумілих результатів, оскільки інструмент намагається призначити текстові символи частинам меж, зображень тощо.