
Nhà cung cấp nhạc trực tuyến Deezer, đã phát hành tin tức gần đây quyết định mở mã nguồn cho một dự án thử nghiệm "Spleeter" nó phát triển như một hệ thống máy học để tách các nguồn âm thanh của các tác phẩm âm thanh phức tạp. Bản thân chương trình cho phép bạn loại bỏ các giọng nói khỏi bố cục và chỉ để lại phần đệm nhạc, điều khiển âm thanh của các nhạc cụ riêng lẻ hoặc thả nhạc và để giọng nói chồng lên một dòng âm thanh khác, tạo các bản mix, karaoke hoặc chuyển soạn.
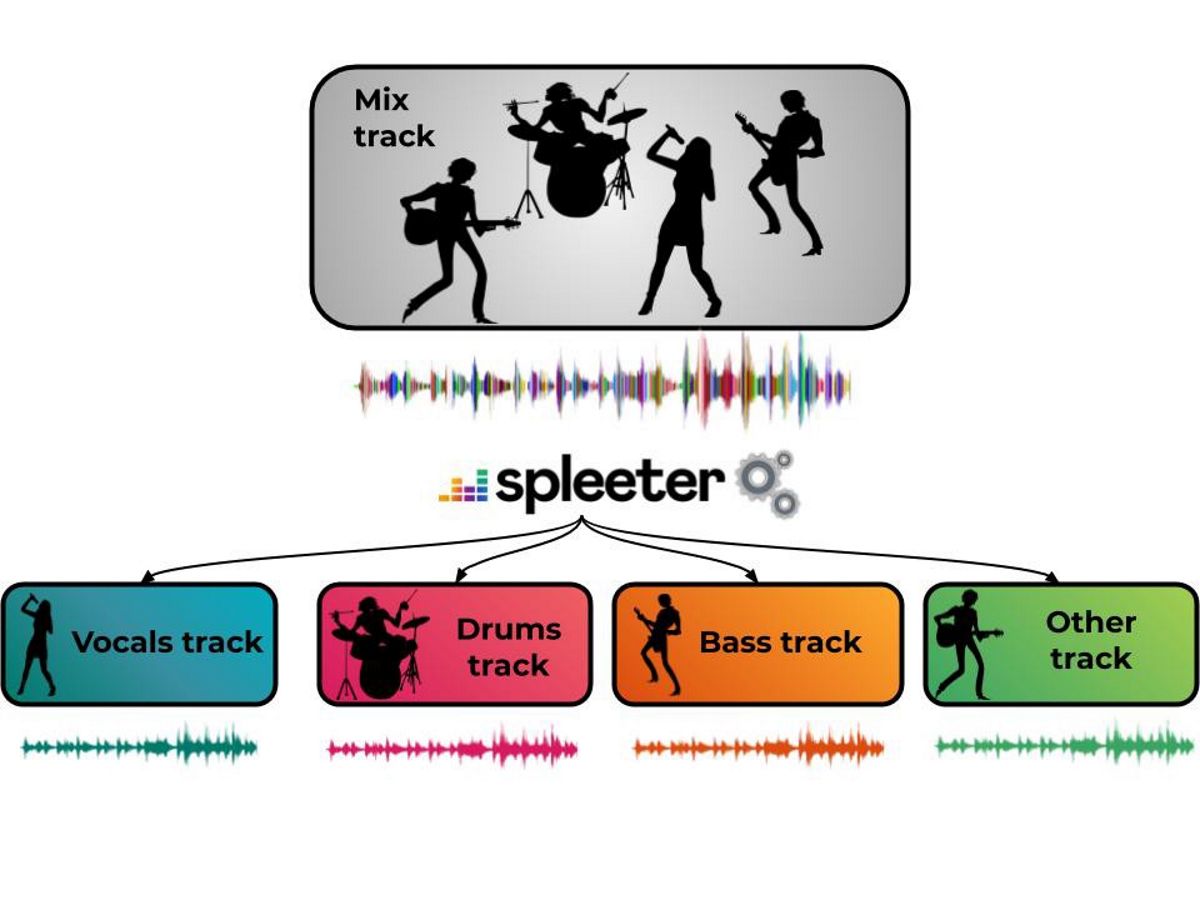
Trong dự án thử nghiệm "Spleeter" này, cung cấp các mô hình đã được đào tạo để tải xuống và tách giọng nói đệm âm thanh, cũng như chia chúng thành 4 và 5 luồng, bao gồm giọng hát, trống, bass, piano và phần còn lại của âm thanh. Spleeter có thể được sử dụng như một thư viện Python hoặc như một tiện ích dòng lệnh độc lập.
Khi chia thành 2 và 4 luồng, Spleeter cung cấp hiệu suất rất caoVí dụ: khi sử dụng GPU, hãy chia tệp âm thanh thành 4 luồng mất ít thời gian hơn 100 lần so với thời lượng của thành phần gốc.
Dưới mui xe, Spleeter là một động cơ được thiết kế và khá phức tạp, nhưng chúng tôi đã làm việc chăm chỉ để làm cho nó thực sự dễ sử dụng. Có thể thực hiện tách biệt thực tế bằng một dòng lệnh duy nhất và nó sẽ hoạt động trên máy tính xách tay của bạn, bất kể hệ điều hành của bạn là gì. Đối với những người dùng nâng cao hơn, có một lớp API Python được gọi là Separator mà bạn có thể thao tác trực tiếp trong đường dẫn thông thường của mình.
Trên hệ thống có GPU NVIDIA GeForce GTX 1080 và CPU 6134 lõi Intel Xeon Gold 32, quá trình thu thập điểm chuẩn musDB, kéo dài ba giờ 27 phút, đã hoàn thành trong 90 giây.
Trong số những lợi thế do Spleeter cung cấp, so với những phát triển khác trong lĩnh vực tách âm, chẳng hạn như dự án mở Open-Unmix, việc sử dụng các mô hình được xây dựng tốt hơn đã được đề cập dựa trên một bộ sưu tập lớn các tệp âm thanh.
Đây là lý do tại sao quyết định của Deezer để phát hành mã Spleeter, vì trong bài đăng về nó, anh ấy nhận xét:
Tại sao lại khởi chạy Spleeter?
Câu trả lời ngắn gọn: chúng tôi sử dụng nó cho nghiên cứu của mình và chúng tôi nghĩ những người khác cũng có thể muốn.
Chúng tôi đã làm việc về phân tách nguồn trong một thời gian dài (và chúng tôi đã có một bài đăng trong ICASSP 2019). Chúng tôi đã so sánh Spleeter với Open-Unmix, một mô hình mã nguồn mở khác được nhóm nghiên cứu Inria phát hành gần đây và báo cáo hiệu suất tốt hơn một chút với tốc độ cao hơn (lưu ý rằng tập dữ liệu đào tạo không giống nhau).
Cuối cùng nhưng không kém phần quan trọng, việc đào tạo những kiểu người mẫu này cần rất nhiều thời gian và năng lượng. Bằng cách làm điều đó một lần và chia sẻ kết quả, chúng tôi hy vọng sẽ giúp những người khác đỡ rắc rối và tài nguyên.
Do hạn chế về bản quyền, các nhà nghiên cứu máy học có quyền truy cập hạn chế vào bộ sưu tập tệp nhạc các mô hình truy cập công cộng khá ít ỏi, trong khi đối với các mô hình Spleeter, chúng được xây dựng bằng dữ liệu từ danh mục nhạc mở rộng của Deezer.
So với các công cụ mở như unmix, Spleeter hoạt động nhanh hơn khoảng 35% trong các điểm chuẩn của CPU, nó hỗ trợ các tệp MP3 và tạo ra kết quả tốt hơn nhiều (trong việc phân bổ phiếu bầu trong Open-Undo, nó trộn lẫn dấu vết của một số công cụ có thể là do các mô hình Open-Unmix được đào tạo trong bộ sưu tập chỉ có 150 bản nhạc).
Mã dự án có dạng thư viện Python dựa trên Tensorflow, với các mô hình được đào tạo trước để tách đường truyền 2, 4 và 5 và được phân phối theo giấy phép MIT. Trong trường hợp đơn giản nhất, hai, bốn hoặc năm tệp có thành phần giọng hát và nhạc đệm (vocal.wav, drum.wav, bass.wav, piano.wav, other.wav) được tạo dựa trên tệp nguồn.
Nếu bạn muốn biết thêm về dự án này, bạn có thể tham khảo liên kết sau hoặc bạn có thể kiểm tra mã nguồn của nó trong liên kết này.
Lá lách sẽ được trình bày và trình diễn trực tiếp tại hội nghị ISMIR 2019 ở Delft.