
流音乐提供商 Deezer,发布了 最近的新闻 决定为“ Spleeter”试验项目开放源代码 展开为 分离声音源的机器学习系统 复杂的声音成分。 该程序本身允许您从乐曲中删除声音,只留下音乐伴奏,操纵单个乐器的声音或放下音乐,并使声音重叠在另一条声音线上,进行混音,卡拉OK或转录。
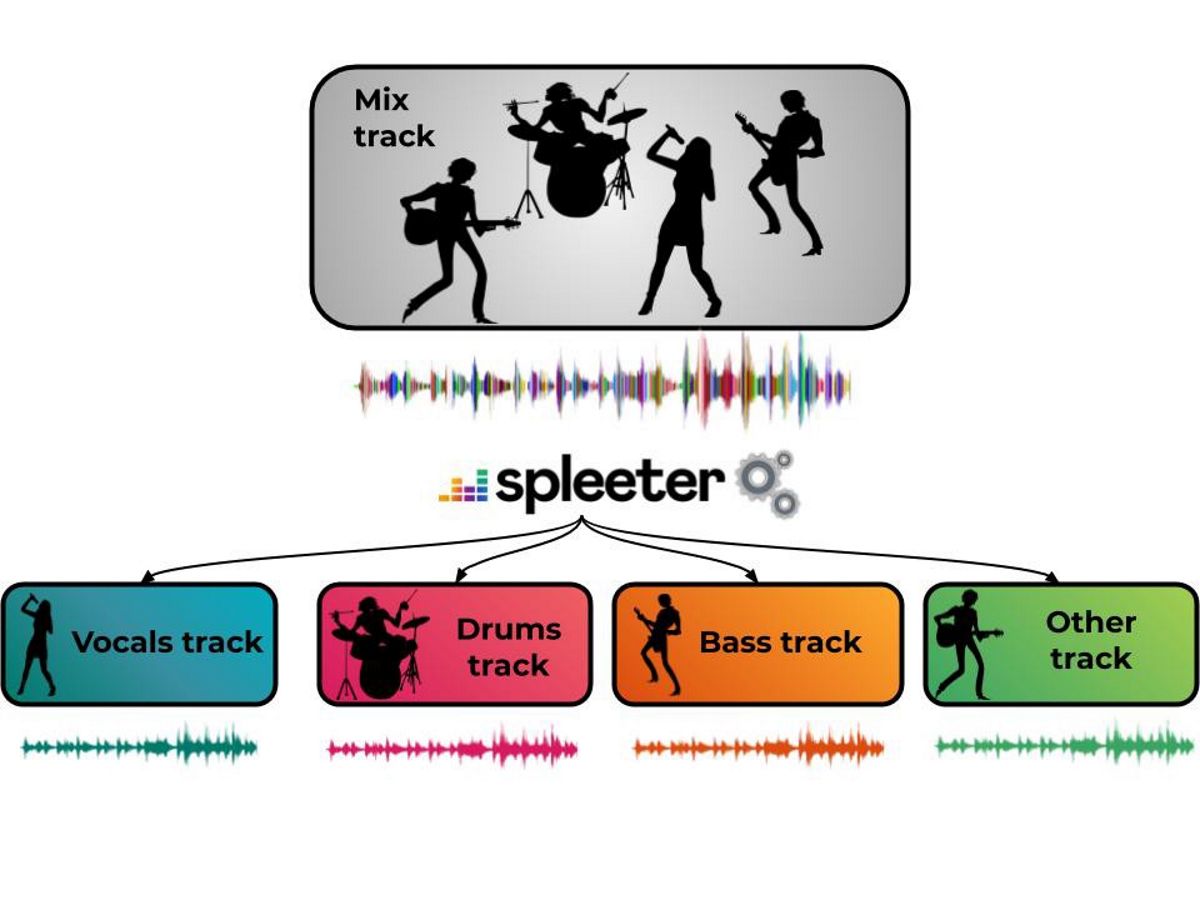
在这个“ Spleeter”试点项目中, 提供已经受过训练的模型以下载和分离声音 声学伴奏 并将它们分为4和5流,包括人声,鼓,贝斯,钢琴和其余声音。 Spleeter可用作Python库或独立的命令行实用程序。
分成2个和4个流时, Spleeter提供非常高的性能例如,使用GPU时,将音频文件分成4个流 所花时间比原始构图的时间少100倍。
在后台,Spleeter是一个相当复杂且设计合理的引擎,但我们一直在努力使它真正易于使用。 实际的分隔可以通过一个命令行来实现,无论您使用什么操作系统,它都可以在您的笔记本电脑上工作。 对于更高级的用户,有一个称为Separator的Python API类,您可以在常规管道中直接进行操作。
在具有NVIDIA GeForce GTX 1080 GPU和6134核Intel Xeon Gold 32 CPU的系统上,musDB测试收集过程持续了三个小时27分钟,并在90秒内完成。
的优势 由Spleeter提供,与声音分离领域的其他发展相比,例如开放项目Open-Unmix, 提到了使用更好的模型 基于大量声音文件。
这就是为什么Deezer的决定 释放Spleeter代码,因为在有关它的文章中,他评论说:
为什么要启动Spleeter?
简短的答案:我们将其用于研究,我们认为其他人可能也希望这样做。
我们一直致力于源代码分离(我们已经在ICASSP 2019中发布了一篇文章)。 我们已将Spleeter与Inria研究团队最近发布的另一种开源模型Open-Unmix进行了比较,并报告了更高的性能和更高的速度(请注意,训练数据集并不相同)。
最后但并非最不重要的是,训练这些类型的模型需要大量时间和精力。 通过一次执行并共享结果,我们希望为他人节省一些麻烦和资源。
由于版权限制,机器学习研究人员 对音乐文件集的访问权限有限 相当少的公共访问模型,而对于Spleeter模型,它们是使用Deezer广泛的音乐目录中的数据构建的。
与unmix等开放式工具相比, Spleeter在CPU基准测试中的执行速度提高了约35%,它支持MP3文件并产生更好的结果(在Open-Undo中分配投票时,它混合了一些工具的痕迹,这可能是由于Open-Unmix模型仅在150个音轨的集合中进行训练)。
项目代码以Python库的形式出现 基于Tensorflow,具有针对2、4和5传输分离的预训练模型 并根据MIT许可进行分发。 在最简单的情况下,将基于源文件创建带有人声和伴奏组件(vocals.wav,drums.wav,bass.wav,piano.wav,other.wav)的两个,四个或五个文件。
如果您想了解更多有关该项目的信息,可以咨询 以下链接 或者您可以检查其源代码 在此链接。
ple 将在代尔夫特举行的ISMIR 2019会议上进行现场演示和演示。