
在下一篇文章中,我們將研究pdftotext。 這是一個開源命令行實用程序,它將使我們能夠 將PDF文件轉換為純文本文件。 基本上,它的作用是從PDF文件中提取文本數據。 該軟件是免費的,並且在許多Gnu / Linux發行版中默認都包含該軟件。
在以下幾行中,我們將看到用於終端的工具,但出於從PDF文件提取文本的相同目的 您也可以使用圖形工具 口徑。 值得注意的是,圖形工具和我們可以在終端中使用的工具, 如果PDF由圖像組成,則它們無法提取文本 (照片,掃描的書籍圖像等。).
在大多數Gnu / Linux發行版中, pdftotext包含在poppler-utils軟件包中。 該工具是一個命令行實用程序, 將PDF文件轉換為純文本。 在其中,我們將找到許多可用的選項,包括指定要轉換的頁面範圍的功能,盡可能保持文本原始物理佈局的功能,設置行尾,甚至使用受密碼保護的PDF文件的功能。 。
在Ubuntu上安裝pdftotext
要在我們的Ubuntu系統上安裝此工具,以防萬一您尚未安裝它,只需打開一個終端(Ctrl + Alt + T)並在其中寫入以下命令即可: 安裝poppler-utils:

sudo apt install poppler-utils
如何使用pdftotext
將PDF文件轉換為文本
在操作系統上安裝軟件包之後,我們可以將PDF文件轉換為純文本。 我們可以 嘗試使用選項保留原始設計 -佈局 使用該命令,但我們也可以嘗試不使用它。 在終端(Ctrl + Alt + T)中,要使用的命令如下:

pdftotext -layout pdf-entrada.pdf pdf-salida.txt
在上一個命令中,您將必須替換 pdf輸入.pdf 以及我們有興趣轉換的PDF文件的名稱,以及 pdf-output.txt 我們要在其中保存輸入的PDF文件的文本的TXT文件的名稱。 如果我們未指定任何輸出文本文件,則pdftotext會自動將文件命名為與原始PDF文件相同的名稱,但擴展名為txt。 可以添加到命令中的另一件有趣的事情是,如果需要的話,文件名之前的路徑(〜/文件/ pdf-input.pdf).
僅將一定範圍的PDF頁面轉換為文本
如果我們對轉換整個PDF文件不感興趣,我們希望 縮小PDF頁面的範圍以轉換為文本 將有 使用-f選項 (要轉換的第一頁)和 -l (最後一頁要轉換),然後是每個選項的頁碼。 使用的命令將類似於以下內容:
pdftotext -layout -f P -l U pdf-entrada.pdf

在上一個命令中,您將必須 用第一頁和最後一頁頁碼替換字母P和U 提取。 的名字 pdf輸入.pdf 我們還必須對其進行更改,並為其指定要使用的PDF文件的名稱。
使用行尾字符
我們可以指定 使用-eol,然後使用mac,dos或unix。 以下命令將添加unix行尾:
pdftotext -layout -eol unix pdf-entrada.pdf
幫助
至 檢查可用選項,運行手冊頁:
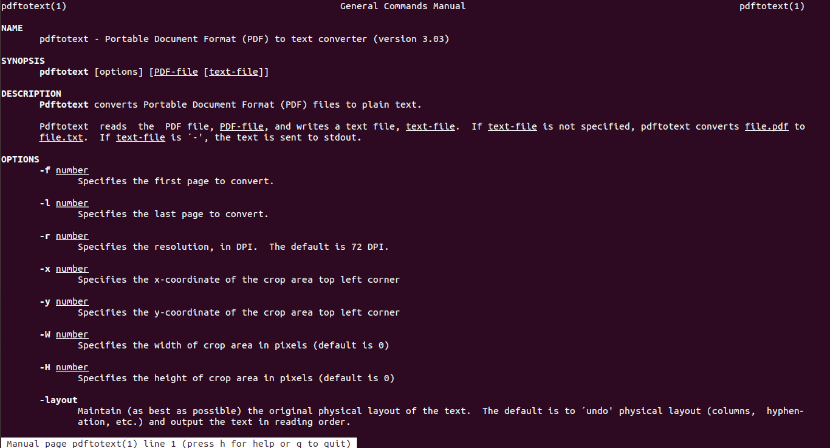
man pdftotext
你也可以 諮詢幫助選項 使用命令:
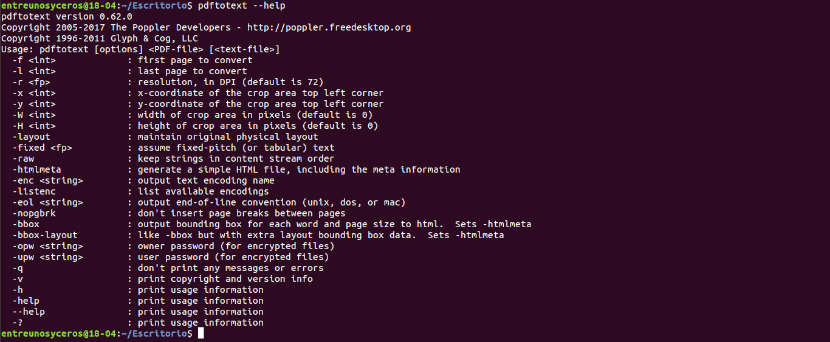
pdftotext --help
使用Bash FOR循環從文件夾轉換PDF文件
如果我們要將文件夾中的所有PDF文件都轉換為文本文件, pdftotext不支持從PDF到文本的批量轉換。 此 我們將能夠使用Bash FOR循環來做到這一點 在終端中(Ctrl + Alt + T):
for file in *.pdf; do pdftotext -layout "$file"; done
至 有關pdftotext的更多信息,您可以諮詢 項目網站。 如果您不想在終端中鍵入命令,也可以 用一個 在線服務 得到相同的結果。
是的,它很好用,但是有時我必須執行OCR或使用Libre Office Draw。
此外,還有許多pdf編輯器。 而且顯然這不會發生在文本圖像上,因此我認為它不實用。
Libre Office Draw既直觀又實用。