
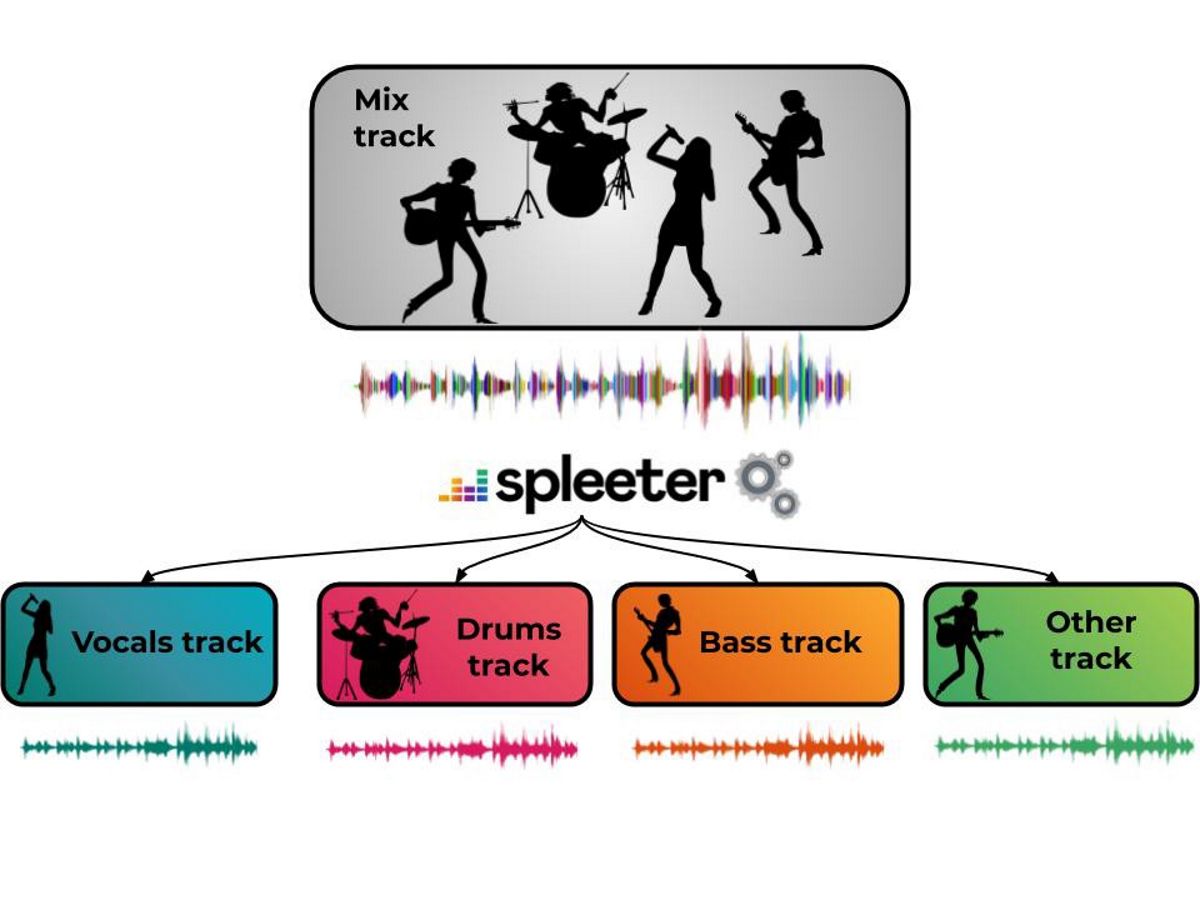
ผู้ให้บริการเพลงสตรีมมิ่ง Deezer เปิดตัวแล้ว ข่าวเมื่อเร็ว ๆ นี้ ตัดสินใจเปิดซอร์สโค้ดสำหรับโครงการนำร่อง "Spleeter" ที่แผ่ออกเป็น ระบบแมชชีนเลิร์นนิงเพื่อแยกแหล่งที่มาของเสียง ขององค์ประกอบเสียงที่ซับซ้อน โปรแกรมนี้ช่วยให้คุณสามารถลบเสียงออกจากการแต่งเพลงและเหลือเพียงเสียงดนตรีประกอบปรับแต่งเสียงของเครื่องดนตรีแต่ละชิ้นหรือวางเพลงแล้วปล่อยให้เสียงทับซ้อนกันบนเส้นเสียงอื่นสร้างมิกซ์คาราโอเกะหรือการถอดเสียง
ในโครงการนำร่อง "Spleeter" นี้ เสนอโมเดลที่ได้รับการฝึกฝนมาแล้วเพื่อดาวน์โหลดและแยกเสียง ประกอบอะคูสติก รวมทั้งแบ่งออกเป็น 4 และ 5 สตรีม ได้แก่ เสียงร้องกลองเบสเปียโนและเสียงที่เหลือ. Spleeter สามารถใช้เป็นไลบรารี Python หรือยูทิลิตี้บรรทัดคำสั่งแบบสแตนด์อโลน
เมื่อแบ่งออกเป็น 2 และ 4 สตรีม Spleeter ให้ประสิทธิภาพสูงมากเช่นเมื่อใช้ GPU ให้แยกไฟล์เสียงออกเป็น 4 สตรีม ใช้เวลาน้อยกว่าระยะเวลาขององค์ประกอบดั้งเดิมถึง 100 เท่า
ภายใต้ฝากระโปรง Spleeter เป็นเครื่องยนต์ที่ค่อนข้างซับซ้อนและได้รับการออกแบบมา แต่เราได้ทำงานอย่างหนักเพื่อให้ใช้งานได้ง่ายจริงๆ การแยกตามจริงสามารถทำได้ด้วยบรรทัดคำสั่งเดียวและควรทำงานบนแล็ปท็อปของคุณโดยไม่คำนึงถึงระบบปฏิบัติการของคุณ สำหรับผู้ใช้ขั้นสูงจะมีคลาส Python API ที่เรียกว่า Separator ซึ่งคุณสามารถจัดการได้โดยตรงในไปป์ไลน์ปกติของคุณ
บนระบบที่มี NVIDIA GeForce GTX 1080 GPU และ 6134-core Intel Xeon Gold 32 CPU การประมวลผลการรวบรวมมาตรฐาน musDB ซึ่งใช้เวลาสามชั่วโมง 27 นาทีเสร็จสิ้นใน 90 วินาที
จากข้อดี นำเสนอโดย Spleeter เมื่อเทียบกับการพัฒนาอื่น ๆ ในด้านการแยกเสียงเช่นโครงการ Open-Unmix แบบเปิด มีการกล่าวถึงการใช้โมเดลที่ดีกว่า ขึ้นอยู่กับคอลเลกชันไฟล์เสียงมากมาย
นี่คือเหตุผลที่ Deezer ตัดสินใจ เพื่อปล่อยรหัส Spleeter เนื่องจากในโพสต์เกี่ยวกับเรื่องนี้เขาแสดงความคิดเห็น:
ทำไมต้องเปิด Spleeter?
คำตอบสั้น ๆ : เราใช้สำหรับการวิจัยของเราและเราคิดว่าคนอื่นอาจต้องการเช่นกัน
เราทำงานเกี่ยวกับการแยกแหล่งที่มาเป็นเวลานาน (และเรามีโพสต์ใน ICASSP 2019 แล้ว) เราได้เปรียบเทียบ Spleeter กับ Open-Unmix ซึ่งเป็นรูปแบบโอเพ่นซอร์สอื่นที่เพิ่งเปิดตัวโดยทีมวิจัยของ Inria และรายงานประสิทธิภาพที่ดีขึ้นเล็กน้อยด้วยความเร็วที่สูงขึ้น (โปรดทราบว่าชุดข้อมูลการฝึกอบรมไม่เหมือนกัน)
สุดท้าย แต่ไม่ท้ายสุดการฝึกโมเดลประเภทนี้ต้องใช้เวลาและพลังงานมาก เราหวังว่าจะช่วยให้ผู้อื่นได้รับความเดือดร้อนและทรัพยากรด้วยการทำเพียงครั้งเดียวและแบ่งปันผลลัพธ์
เนื่องจากข้อ จำกัด ด้านลิขสิทธิ์, นักวิจัยแมชชีนเลิร์นนิง สามารถเข้าถึงคอลเล็กชันไฟล์เพลงได้อย่าง จำกัด โมเดลการเข้าถึงสาธารณะค่อนข้างน้อยในขณะที่รุ่น Spleeter ถูกสร้างขึ้นโดยใช้ข้อมูลจากแคตตาล็อกเพลงที่กว้างขวางของ Deezer
เมื่อเปรียบเทียบกับเครื่องมือแบบเปิดเช่น unmix Spleeter ทำงานได้เร็วขึ้นประมาณ 35% ในเกณฑ์มาตรฐานของ CPUรองรับไฟล์ MP3 และสร้างผลลัพธ์ที่ดีกว่ามาก (ในการจัดสรรคะแนนโหวตใน Open-Undo จะผสมผสานร่องรอยของเครื่องมือบางอย่างที่อาจเกิดจากความจริงที่ว่าโมเดล Open-Unmix ได้รับการฝึกฝนในคอลเลคชันเพียง 150 แทร็ก)
รหัสโครงการมาในรูปแบบของไลบรารี Python ขึ้นอยู่กับ Tensorflow โดยมีรุ่นที่ผ่านการฝึกอบรมแล้วสำหรับการแยกการส่ง 2, 4 และ 5 และจัดจำหน่ายภายใต้ใบอนุญาต MIT ในกรณีที่ง่ายที่สุดไฟล์สอง, สี่หรือห้าไฟล์ที่มีเสียงร้องและส่วนประกอบประกอบ (vocals.wav, drums.wav, bass.wav, piano.wav, other.wav) จะถูกสร้างขึ้นตามไฟล์ต้นฉบับ
หากต้องการทราบข้อมูลเพิ่มเติมเกี่ยวกับโครงการนี้สามารถปรึกษาได้ ลิงค์ต่อไปนี้ หรือคุณสามารถตรวจสอบซอร์สโค้ดได้ ในลิงค์นี้
ม้าม จะถูกนำเสนอและแสดงสดในการประชุม ISMIR 2019 ในเดลฟต์