A következő cikkben a TextSnatcherrel fogunk foglalkozni. Ha Ön azon felhasználók közé tartozik, akik általában együtt dolgoznak OCR, akkor érdemes látni egy egyszerű alkalmazást, amely egy ehhez hasonló nagyszerű összetett alkalmazásra épül Tesseract. ha keresed egy egyszerű és egyszerű módja a szöveg másolásának a képekről Gnu/Linux alatt, akkor vessen egy pillantást a TextSnatcherre, lehet, hogy megfelel annak, amit keres.
La posibilidad de szöveget kivonat képekből, PDF-fájlokból vagy hasonló dolgokból, nem újdonság. Manapság számos különféle eszközt találhatunk ehhez a feladathoz, de jelenleg egyik sem teszi ezt olyan könnyen, mint a TextSnatcher.
Ez az eszköz optikai karakterfelismerést hajt végre (OCR) másodpercek alatt, ami lehetővé teszi a felhasználók számára gyorsan másoljon szöveget a képernyőn látható bármiről a rendszer vágólapjára, így készen áll máshova beillesztésre. Karakterfelismerés, gyakran OCR (az angol optikai karakterfelismerésből), egy szövegek digitalizálását célzó folyamat, amely egy kép alapján automatikusan azonosítja az adott ábécéhez tartozó szimbólumokat vagy karaktereket, majd adatként tárolja azokat. Ezekkel tehát egy szövegszerkesztő programmal tudunk kölcsönhatásba lépni.
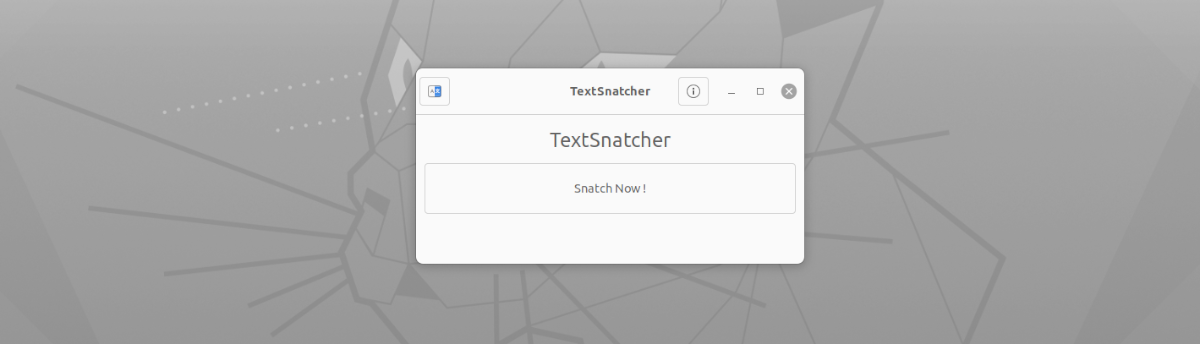
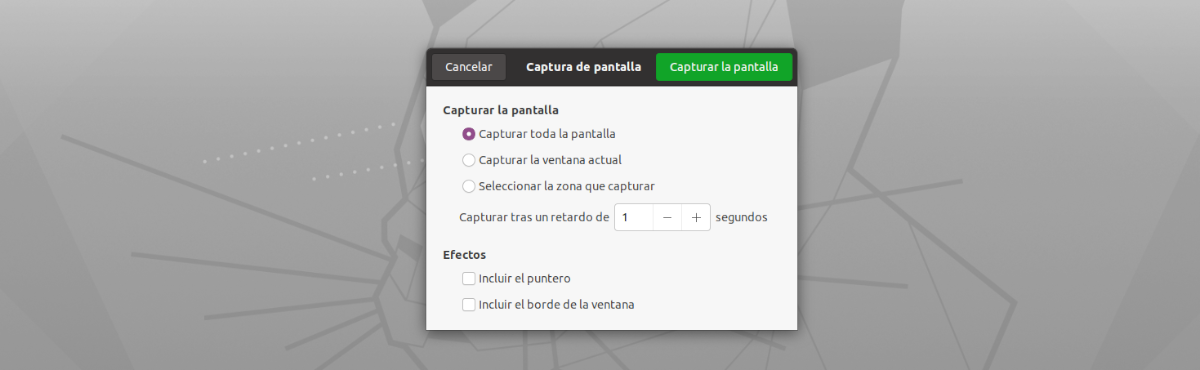
Ami ennek az alkalmazásnak a felületét illeti, nem is lehetne könnyebben használható. Már csak el kell indítanunk, kattintson a 'Snatch Now!' gombra. Utána látni fogjuk az alapértelmezett képernyőrögzítő eszközt a teljes képernyős rögzítéshez, az aktuális ablak rögzítéséhez vagy a rögzíteni kívánt terület kiválasztásához (ajánlott) csak a másolni kívánt szövegre összpontosítva.
A TextSnatcher általános jellemzői
- Ez a program lehetővé teszi számunkra Könnyedén másolhatja a képek szövegét, másodpercek alatt elvégezhetjük az OCR műveleteket, elég jó eredménnyel.
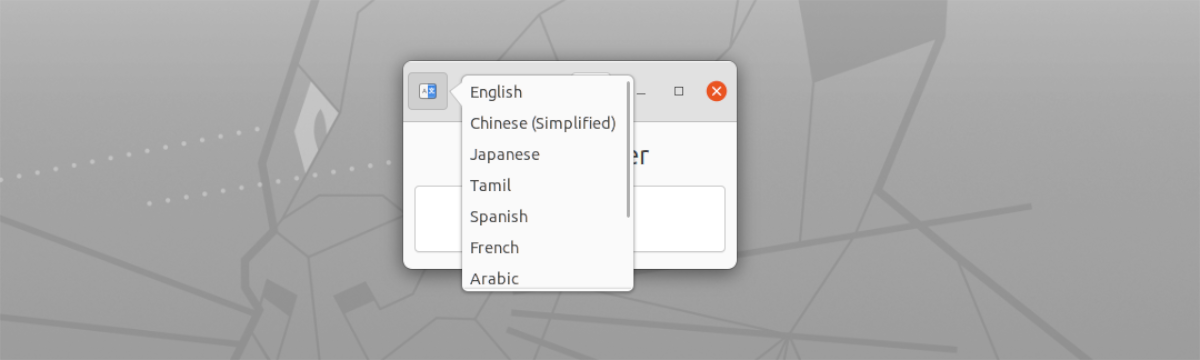
- Fiók a következővel: több nyelv támogatása. Ezeket a bal oldalon, az ablak tetején található gombbal lehet kiválasztani.
- Megengedi nekünk másolja ki a képek szövegét a terület kiválasztásával.
- van gyors és könnyen használható program.
- Lehet nézzen meg néhány videót a program működéséről az ő GitHub tárház.
- Ez a kb a karakterfelismeréshez a Tesseract OCR 4.x-et használja. Ha többet szeretne tudni, olvassa el Tesseract y Star Tesseact-projekt.
Telepítse a TextSnatcher-t Ubuntu-ra
Ez a program megtalálható Flatpak csomagban a címen Flathub. Ha az Ubuntu 20.04-et használja, és még mindig nincs engedélyezve ez a technológia a rendszerén, folytathatja Az útmutató hogy egy kolléga írt erre a blogra egy ideje.
hogy telepítse ezt a programot Ubuntu-ra, csak egy terminált kell megnyitnunk (Ctrl + Alt + T), és végre kell hajtanunk a benne lévő parancsot:
flatpak install flathub com.github.rajsolai.textsnatcher
A program telepítése után már csak meg kell keresnünk az indítót a számítógépünkön, vagy futni a terminálban, hogy indítsa el a programot:

flatpak run com.github.rajsolai.textsnatcher
Ha a szoftver elindítása után nem működik megfelelően, vagy egyáltalán nem indul el, előfordulhat, hogy telepítenie kell gnome-screenshot. Ebben az esetben nem kell mást tennie, mint beírni egy terminált (Ctrl+Alt+T):
sudo apt install gnome-screenshot
eltávolítást
Ha akarod távolítsa el a programot a rendszerből, akkor csak egy terminált (Ctrl+Alt+T) kell megnyitni, és elindítani benne a parancsot:

flatpak uninstall com.github.rajsolai.textsnatcher
Ezt az eszközt különböző operációs rendszerekhez tervezték. Bár a cikk megírásához csak Ubuntu 20.04/21.10-en teszteltem, mindkét esetben jó eredménnyel. A motor A Tesseract OCR támogatja ezt az eszközt, és kiválóan működik, ha a kiválasztott terület nagy felbontású, vagy a másolandó szöveg nagy és tiszta..
Alacsony felbontású vagy nagyon kis "szöveg" blokkokban egyes karaktereket néha nagyobbra másol a rendszer. Ha a kijelölés sok díszítéssel rendelkezik, az érthetetlen eredményhez vezethet, mivel az eszköz megpróbál szövegkaraktereket rendelni a keretek, képek stb. részeihez.