
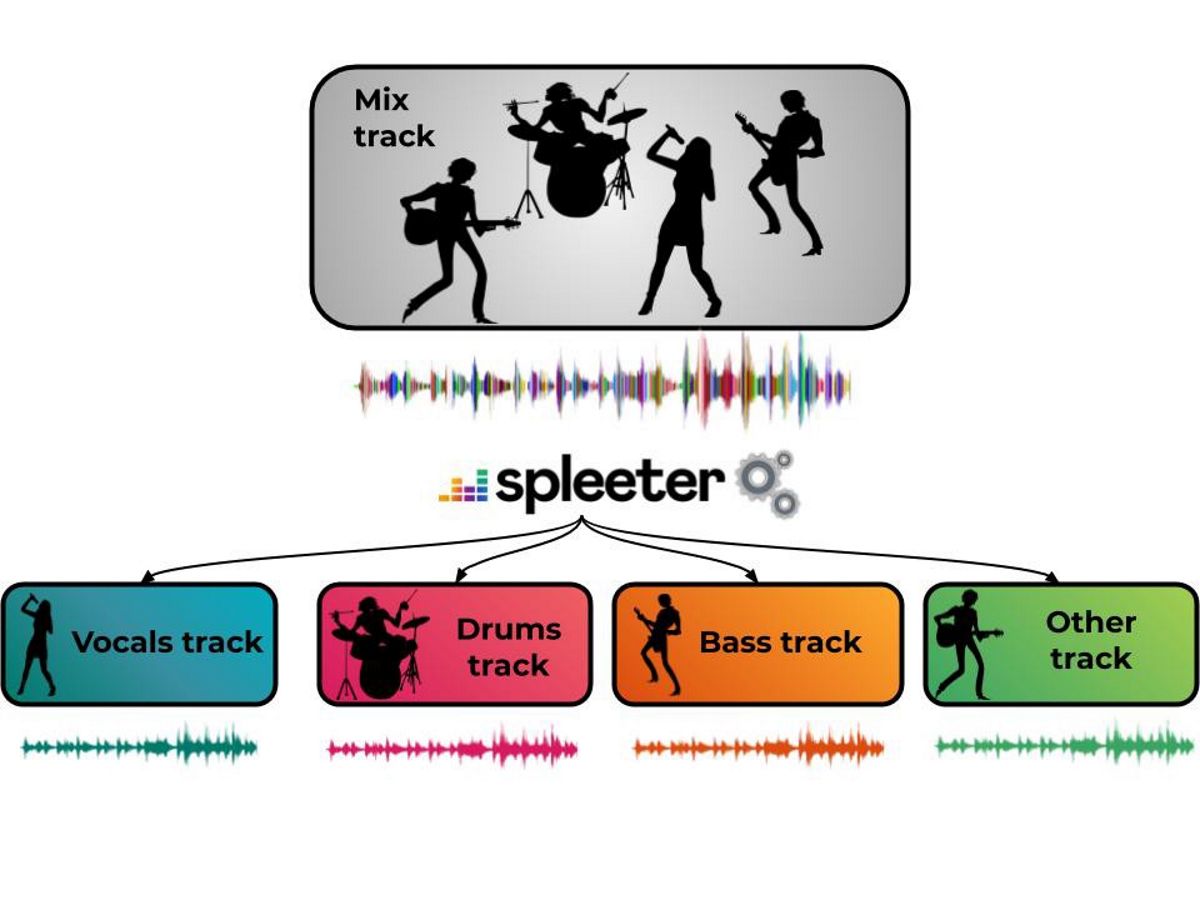
Ofruesi i muzikës streaming Deezer, i lëshuar lajmet që së fundmi vendosi të hapë kodin burimor për një projekt pilot "Spleeter" që zhvillohet si një sistem i të mësuarit makinerik për të ndarë burimet e zërit të kompozimeve komplekse zanore. Vetë programi ju lejon të hiqni zërat nga përbërja dhe të lini vetëm shoqërimin muzikor, të manipuloni tingullin e instrumenteve individuale ose të lëshoni muzikë dhe ta lini zërin të mbivendoset në një linjë tjetër tingulli, të krijoni përzierje, karaoke ose transkriptim.
Në këtë projekt pilot "Spleeter", ofroni modele të trajnuara tashmë për të shkarkuar dhe për të ndarë zërat shoqërimi akustik, si dhe për t'i ndarë ato në 4 dhe 5 rryma, përfshirë vokalin, daullet, basin, pianon dhe pjesën tjetër të tingullit. Spleeter mund të përdoret si një bibliotekë Python ose si një vegël e pavarur e linjës komanduese.
Kur ndaheni në 2 dhe 4 rrjedha, Spleeter siguron performancë shumë të lartëp.sh. kur përdorni GPU, ndani një skedar audio në 4 rrjedha merr 100 herë më pak kohë sesa kohëzgjatja e përbërjes origjinale.
Nën kapak, Spleeter është një motor mjaft kompleks dhe i projektuar, por ne kemi punuar shumë për ta bërë atë me të vërtetë të lehtë për t'u përdorur. Ndarja aktuale mund të arrihet me një rresht të vetëm komandimi dhe duhet të funksionojë në laptopin tuaj, pavarësisht nga sistemi juaj operativ. Për përdoruesit më të përparuar, ekziston një klasë Python API e quajtur Separator që mund ta manipuloni direkt në tubacionin tuaj të zakonshëm.
Në një sistem me një GPU NVIDIA GeForce GTX 1080 dhe një CPU 6134-bërthamor Intel Xeon Gold 32, përpunimi i mbledhjes së vlerësimeve musDB, i cili zgjati tre orë dhe 27 minuta, përfundoi në 90 sekonda.
Nga avantazhet ofruar nga Spleeter, krahasuar me zhvillimet e tjera në fushën e ndarjes së zërit, siç është projekti i hapur Open-Unmix, përmendet përdorimi i modeleve të ndërtuara më mirë bazuar në një koleksion të gjerë të skedarëve të zërit.
Ja pse vendimi i Deezer për të lëshuar kodin Spleeter, sepse në postimin për të, ai komenton:
Pse të nisë Spleeter?
Përgjigje e shkurtër: ne e përdorim atë për hulumtimin tonë dhe mendojmë se edhe të tjerët mund të dëshirojnë.
Ne kemi punuar për ndarjen e burimit për një kohë të gjatë (dhe ne tashmë kishim një postim në ICASSP 2019). Ne kemi krahasuar Spleeter me Open-Unmix, një model tjetër me burim të hapur i lëshuar kohët e fundit nga një ekip hulumtues Inria, dhe raportuam performanca pak më të mira me shpejtësi më të lartë (vini re se databaza e trajnimit nuk është e njëjta)
E fundit, por jo më pak e rëndësishmja, trajnimi i këtyre llojeve të modeleve kërkon shumë kohë dhe energji. Duke e bërë atë një herë dhe duke ndarë rezultatin, ne shpresojmë t'i kursejmë të tjerëve disa telashe dhe burime.
Për shkak të kufizimeve të së drejtës së autorit, studiuesit e mësimit makinerik kanë qasje të kufizuar në koleksionet e skedarëve muzikorë modele mjaft të pakta të aksesit publik, ndërsa për modelet Spleeter ato u ndërtuan duke përdorur të dhëna nga katalogu i gjerë muzikor i Deezer.
Në krahasim me mjetet e hapura si unmix, Spleeter performon afërsisht 35% më shpejt në standardet e CPU-së, ajo mbështet skedarët MP3 dhe gjeneron rezultate shumë më të mira (në alokimin e votave në Open-Undo ajo përzien gjurmët e disa mjeteve që ndoshta janë për shkak të faktit se modelet Open-Unmix janë trajnuar në koleksione të vetëm 150 këngëve).
Kodi i projektit vjen në formën e një biblioteke Python bazuar në Tensorflow, me modele të para-trajnuara për ndarjen e transmetimit 2, 4 dhe 5 dhe shpërndahet nën licencën MIT. Në rastin më të thjeshtë, dy, katër ose pesë skedarë me vokal dhe përbërës shoqërues (vocals.wav, daulle.wav, bass.wav, piano.wav, other.wav) krijohen bazuar në skedarin burimor.
Nëse doni të dini më shumë rreth këtij projekti, mund të konsultoheni lidhja e mëposhtme ose mund të kontrolloni kodin burimor të tij në këtë lidhje.
Zeshkane do të prezantohet dhe demonstrohet drejtpërdrejt në konferencën ISMIR 2019 në Delft.